HAProxyにコントリビュートした話
さくらインターネット Advent Calendar 2021 10日目の記事です。
日頃、運用や新機能の開発を行っているさくらのクラウドの「エンハンスドロードバランサ」はL7のロードバランサのソフトウェアとしてHAProxyを使っています。
こちらの記事でシステム構成について紹介しております。
また、本blogにてlibslzによるHTTPレスポンスのGZIP圧縮の紹介もしています。
この記事はHAProxyの運用で問題を発見し解決した話と、HAProxyにissue報告した話になります。
発見から問題特定まで
とある作業後、エンハンスドロードバランサのL7ロードバランサであるHAProxyのうちの一つのプロセスが異常にCPUを使っているのを発見しました。
このHAProxyのプロセスはCPU 1コアを使い切っている状態になっておりました。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28007 haproxy 20 0 570272 11612 924 S 99.0 0.2 0:31.57 /usr/local/sbin/haproxy
エンハンスドロードバランサでは、1つのロードバランサ設定ごとにhaproxyのプロセスが割り当てられます。他を確認したところ、特定の1つの設定でのみ起きている問題で、他のお客様の設定では発生しておりませんでした。
負荷の原因としてロードバランサへの攻撃や定期的な突発アクセスを想定し、アクセスログの調査をしましたが、そのような形跡はありませんでした。
次にtopコマンドで観察していると、CPUがbusyとなる状態は定期的に発生し、10秒程度継続して元にもどるように見えたので、同じ間隔で設定されている実サーバへのヘルスチェック時になにか起きていそうだと当たりをつけ、今度は strace でそのタイミングを捉えてみると、次のようなトレースが取得できました
[pid 28015] connect(31, {sa_family=AF_INET, sin_port=htons(443), sin_addr=inet_addr("198.51.100.123")}, 16) = -1 EINPROGRESS (Operation now in progress)
[pid 28015] epoll_ctl(30, EPOLL_CTL_ADD, 31, {EPOLLIN|EPOLLOUT|EPOLLRDHUP, {u32=31, u64=31}}) = 0
[pid 28015] clock_gettime(CLOCK_THREAD_CPUTIME_ID, {89, 485590665}) = 0
[pid 28015] epoll_wait(30, [{EPOLLOUT, {u32=31, u64=31}}], 200, 2556) = 1
[pid 28015] clock_gettime(CLOCK_THREAD_CPUTIME_ID, {89, 485637316}) = 0
[pid 28015] recvfrom(31, 0x7f14740342d0, 16320, 0, NULL, NULL) = -1 EAGAIN (Resource temporarily unavailable)
[pid 28015] sendto(31, "HEAD /health-check.html HTTP/1."..., 93, MSG_DONTWAIT|MSG_NOSIGNAL, NULL, 0) = 93
[pid 28015] epoll_ctl(30, EPOLL_CTL_MOD, 31, {EPOLLIN|EPOLLRDHUP, {u32=31, u64=31}}) = 0
[pid 28015] clock_gettime(CLOCK_THREAD_CPUTIME_ID, {89, 485774729}) = 0
[pid 28015] epoll_wait(30, [{EPOLLIN|EPOLLRDHUP, {u32=31, u64=31}}], 200, 2554) = 1
[pid 28015] clock_gettime(CLOCK_THREAD_CPUTIME_ID, {89, 485839265}) = 0
[pid 28015] recvfrom(31, "<!DOCTYPE HTML PUBLIC \"-//IETF//"..., 16320, 0, NULL, NULL) = 565
#ここで止まる
この結果から、ヘルスチェックのため実サーバである 198.51.100.123 のポート443に対してアクセスし、このタイミングでCPU負荷が上がる状態に陥っていることがわかり、また、(おそらく)SSL有効なポートに対して生TCPでアクセス(お客様の設定の間違いのようですが)してしまった結果、HTTPのレスポンスヘッダがなく、いきなりエラーを知らせるHTMLが返ってきていることもこのトレースからわかりました。
HTTPSのポートにHTTP通信を行った際に、HTTPレスポンスヘッダがなくコンテンツが返るのはイレギュラーのようで、手元にあるいくつかのWebサーバ調べましたが、Nginxなど大体のWebサーバはHTTPヘッダを返しています。
検証とパッチ作成
このHTTPヘッダを返さない実サーバが問題を引き起こしているのではないかということで、Go言語で同じ動きをするサーバを作成し、手元で動かして検証しました。
動かしたGoのサーバはこれです。Goは雑(すぐ)にかけていいですね
問題が再現できるhaproxyの最小限の設定を作成し
global
log stdout format raw local0
defaults
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
frontend 113300002882-163.43.241.14:80
mode http
bind 0.0.0.0:8080
default_backend 113300002882-backend-default
backend 113300002882-backend-default
mode http
option httpchk GET /live
server 127.0.0.1:12345 127.0.0.1:12345 check inter 10s
ヘルスチェックのコードにてprintf debugで問題箇所の特定を行い、以下のpatchを作成しました。
1日がかりで結構時間かけた割には、変更は30文字にも満たないpatchとなりました。
問題の原因としては、通信が切れたにもかかわらず、HTTPヘッダを探すためヘルスチェックのタイムアウトまで次のパケットを読み込もうとしてループしてしまうことで、このpatchで通信が切れていた場合、次のデータをまたずに即時エラーとするようにしています。
このpatchを、エンハンスドロードバランサの開発環境に適用し、busy loopが解消していること、また他の問題のでないことを確認し、順次本番環境へも導入していきました。
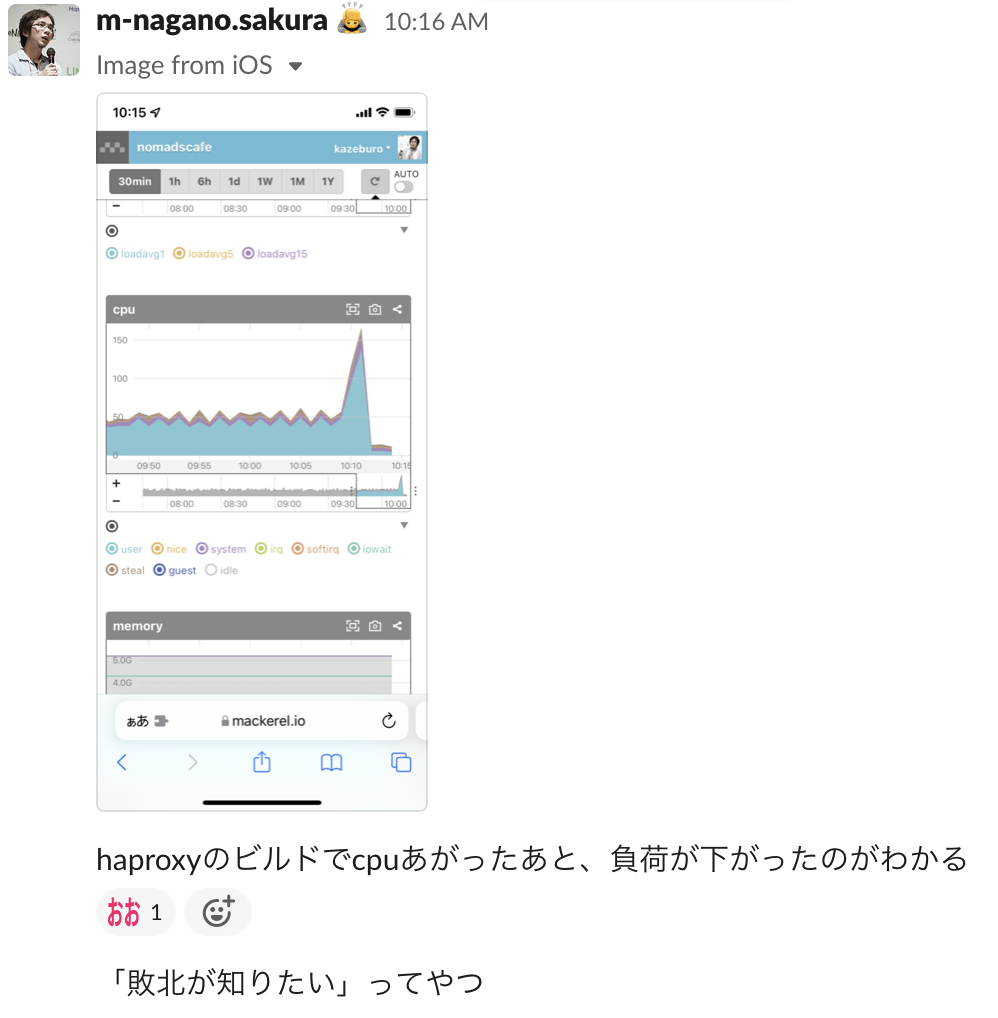
勝利の瞬間です
haproxyへのコントリビュート
HAProxyはOSSですから、この問題についてissueをあげてコントリビュートをすることにしました。
登録したissueはこちら
送ったpatchは少し内容が変わりましたが、問題箇所の認識は間違ってなかったようで
取り込まれて、haproxy 2.4.8 に含まれる形でリリースされました。
http://www.haproxy.org/download/2.4/src/CHANGELOG
- BUG/MEDIUM: tcpcheck: Properly catch early HTTP parsing errors
これが今回の修正にあたります。
非常にニッチなものではあり、感想も月並みではありますが、サービスの中で使用しているOSSに対するissue報告とコントリビュートができて良かったです。
OSSなソフトウェアの開発・運用上発見した問題があれば、今後とも積極的にコントリビュートしていきます。