さくらのクラウド DNSアプライアンスで HTTPS RR を試してみた
さくらインターネット Advent Calendar 2021 7日目の記事です。
DNSコンテンツサーバ機能を提供するさくらのクラウドの「DNSアプライアンス」では、2021年9月からHTTPSリソースレコード・SVCBリソースレコードをサポートしています。
こちらの紹介記事になります。
HTTPSリソースレコード(HTTPS RR)とは、DNSでHTTPSサーバに接続する際のALPNなどのパラメータを渡すことができる新しいDNSのレコードタイプで、CNAMEと異なりZone APEXにも設定ができるのが特徴です。また、HTTPSレコードがある場合、初回からHTTPS接続を行うHSTS(HTTP Strict Transport Security)としても利用されます。CDNのcloudflareやiOSのSafariではすでにデフォルトで使われております。
HTTPS RR・SVCB RRについては以下の記事も参考になります
HTTP RRの仕様は近いうちにRFCになるかと思います。
HTTP/3対応のサーバの準備
まず、実験に使うサーバを用意します。
さくらのクラウドの仮想サーバを1台作成します。今回はOSにRocky Linux 8.5を使いました。
サーバ起動後、必要なポートを開けます
$ sudo firewall-cmd --permanent --add-service=http $ sudo firewall-cmd --permanent --add-service=https $ sudo firewall-cmd --permanent --add-port=443/udp $ sudo firewall-cmd --reload
今回の実験ではWebサーバとしてHTTP/3が利用できる Caddy というサーバを使います。
CaddyはGoで書かれており、HTTPS周りの設定を自動で行ったり、Let's EncryptやZeroSSLから証明書を取得してインストールしてくれるなど便利なやつです。
Caddyのインストールはこちらにドキュメントがあります。今回はdnf/rpm系OSなので、
$ sudo dnf install 'dnf-command(copr)' $ sudo dnf copr enable @caddy/caddy $ sudo dnf install caddy $ sudo systemctl start caddy $ sudo systemctl enable caddy
この手順でインストールと起動ができました。
Caddyのデフォルトの設定は /etc/caddy/Caddyfile にあり、コメントを除くと
:80 {
# Set this path to your site's directory.
root * /usr/share/caddy
# Enable the static file server.
file_server
}
のようになってました。癖のある設定ファイルですが、 /usr/share/caddy をドキュメントルートして、静的なファイル配信を行うサーバが port 80 で起動します。
ブラウザからIPアドレスでアクセスするとやや斜めに傾いたデフォルトのページがみれました。

これでCaddyのセットアップは一旦OKです。
DNSレコードの登録
まずは、通常のAレコードからさくらのクラウドのコントロールパネルから追加します。

次に、HTTPSレコードも登録
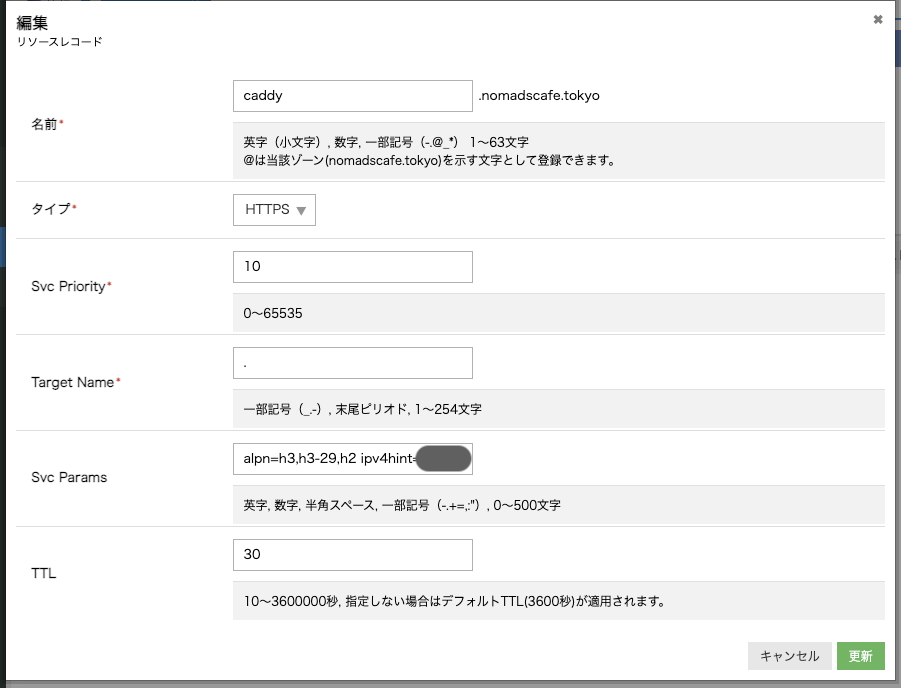
HTTP RRでは、Svc Priorityに 0 を入れるとエイリアスモードとなります。Zone APEXに指定する際などに使います。今回はエイリアスではないので適当な数値 10 を入れています。
Target Nameはホスト名になりますが、. (ドット) を入れることで同名のAレコードを参照するよう指定できます。
Svc ParamsにサーバにHTTPS接続する際のパラメータを入力します。
alpn=h3,h3-29,h2 ipv4hint=198.51.100.133
CaddyはHTTP/3(h3, h3-29)、HTTP2に対応しているのでALPNをこのように指定しました。ipv4hintのIPはAレコードのIPアドレスと同じです。
登録ができたら、Google Public DNSを使って確認してみます。
{
"Status": 0,
"TC": false,
"RD": true,
"RA": true,
"AD": false,
"CD": false,
"Question": [
{
"name": "caddy.nomadscafe.tokyo.",
"type": 65
}
],
"Answer": [
{
"name": "caddy.nomadscafe.tokyo.",
"type": 65,
"TTL": 30,
"data": "10 . alpn=h3,h3-29,h2 ipv4hint=198.51.100.133"
}
],
"Comment": "Response from ."
}
Caddyの設定
デフォルトではポート80をlistenしているだけなので、HTTPSが利用できるよう設定を変更します。
{
servers :443 {
protocol {
experimental_http3
}
}
}
caddy.nomadscafe.tokyo {
log
root * /usr/share/caddy
file_server
}
これでサーバを再起動すると、HTTP/3を有効にして caddy.nomadscafe.tokyo の証明書取得も行ってくれました。

ブラウザからのHTTPSのアクセスも問題なくできました。Firefoxの開発ツールでHTTP/3で通信していることも確認できました。

Firefoxでは、HTTPS RRの使用が、DNS over HTTPS (DoH)を使用したときに限られています。about:networking とURL入力欄に打ち込むとDNS照会ツールが使えるので、これを使って確認します。
まず、DoHを使用しない場合

HTTP RRは空っぽです。次に DoHを有効にした場合 (cloudflareを使いました)

HTTP RRの欄にHTTPSレコードに入力したものが表示されました。
Aレコードを消して HTTPS レコードを試す
このままでは HTTPS レコードを使ってアクセスしているのか分かりにくいので、Aレコードを消してみることにしました。

svc.nomadscafe.tokyo として新しいAレコードを置き、caddy.nomadscafe.tokyo の Target Nameをそちらに向け、caddy.nomadscafe.tokyo の Aレコードを削除しました。

IPアドレスがUNKOWNになりましたが、HTTPS レコードは表示されます。DoHの有効のFirefoxブラウザでのアクセスもできました。
ただし、リロードを繰り返すとタイミングによって名前解決に失敗したエラーがでることがあります。これは about:config で network.dns.force_waiting_https_rr を true にすることで出なくなりますが、Aレコードがないのがおそらく異常なので、この設定を常用する必要はありません。
macOS CatalinaのSafariはHTTPS RRに対応していないのでアクセスができません。

macOS Big SurやiOS 15のSafariでは特に設定なくアクセスできました。

Chrome(96.0.4664.93)は対応していないのかDoHを有効にしてもアクセスできませんでした。
まとめ
ということで、HTTPSリソースレコードを使って、実験をしてみました。現状メリットが大きいものではないですが、今後使われるようになっていくのでしょう。お試しあれ~
PerlなプロジェクトをGithub Actionsでコンテナ化 (ARM64対応)
この記事は Perl Advent Calendar 2021 の6日目の記事です。
業務では日頃はGo、Perl、PHPを使ってクラウドのバックエンドを作り、JavaScript/TypeScriptでフロントエンドを作っています
この記事は昔からherokuで動かしていたサービスをコンテナ化してGraviton2なEC2インスタンス上でk3sでシングルサーバクラスタを作成して動かしているよという紹介です。
対象は以下の2つ
それぞれのGitHubのrepositoryはこちら
このサービスで使うDockerコンテナはGitHub Actionsで作成し、GitHubのContainer Registoryにあげています。
サーバがGraviton2なので、ARM64に対応したコンテナが必要となりますが、それもGitHub Actionsでビルドしています。
Dockerfile の用意
Perlの公式コンテナイメージは多くののプラットフォームをサポートし、ARM64にも対応しています。

なのでこれを元にするDockerfileを作成しました。
tanzakではこんな感じ
FROM perl:5.32 RUN mkdir -p /opt/app RUN cpanm -n Carton COPY ./cpanfile /opt/app/cpanfile COPY ./cpanfile.snapshot /opt/app/cpanfile.snapshot WORKDIR /opt/app RUN carton install --deployment EXPOSE 5000 COPY . /opt/app CMD carton exec -- plackup -s Starlet --max-workers=3 --port 5000 -a app.psgi
workflowファイル
そしてDockerビルドするGitHub Actionsのworkflowファイルはこんな感じです
name: Build and Publish Docker
on:
push:
branches:
- master
jobs:
build_and_push:
runs-on: ubuntu-latest
env:
IMAGE_NAME: tanzak
steps:
- name: checkout
uses: actions/checkout@v2
- name: Set up QEMU
uses: docker/setup-qemu-action@v1
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v1
- name: Login to GitHub Container Registry
uses: docker/login-action@v1
with:
registry: ghcr.io
username: ${{ github.repository_owner }}
password: ${{ secrets.CR_PAT }}
- name: Get short SHA
id: slug
run: echo "::set-output name=sha8::$(echo ${{ github.sha }} | cut -c1-8)"
- name: Build and push
uses: docker/build-push-action@v2
with:
context: .
push: true
platforms: linux/amd64,linux/arm64
tags: |
ghcr.io/${{ github.repository_owner }}/${{ env.IMAGE_NAME }}:latest
ghcr.io/${{ github.repository_owner }}/${{ env.IMAGE_NAME }}:${{ steps.slug.outputs.sha8 }}
マルチアーキテクチャのビルドをするために、 docker/setup-qemu-action および docker/setup-buildx-action を利用し、docker/build-push-action で platformsとして linux/amd64,linux/arm64 を指定しています。
これでビルドはできました。
GitHub Container Registoryでも、amd64/arm64の2つのアーキテクチャでイメージが上がっているのが確認できます。
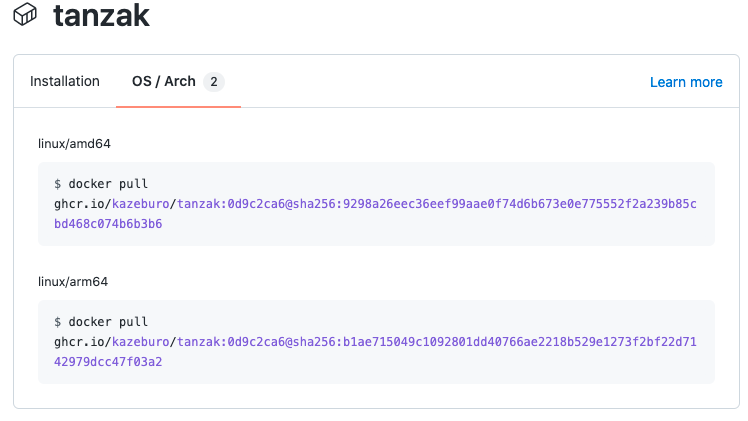
https://github.com/kazeburo/tanzak/pkgs/container/tanzak
はげしく便利ではあるのですが、すごーく時間がかかります

まとめ
PerlなプロジェクトでもGitHub Actionsを使いARM64のDockerイメージがビルドできました。これで昔々から動かしているサービスでもGraviton2の恩恵を受けてお安く運用できてます。
Graviton2を採用したAWSのEC2はx86系と比較して20%安くなっているとされています。各種マネージドサービスもそろってきました。開発環境やテスト環境がx86の場合の課題もありますが、うまく使っていけるとよさそうです。
sacloud/autoscaler とさくらのクラウドのアクティビティグラフで実現するオートスケール
前回の続きになります。
前回は autoscaler のコアサーバを起動し、cliからサーバの台数を増減させる水平スケールを試しました。今回はさくらのクラウドに備わるアクティビティグラフの情報を使い、自動でスケールアウト・インを行うオートスケールを試します。
設定
2022/3/4 追記
autoscaler v0.5.0 からコマンド体系および、設定が変更になっています。 以下のgistに動作確認した設定ファイルを置いています
autoscalerのインストールおよび基本的な設定は前回の記事を参考にしてください。 autoscaler_coreの設定は以下のようにしました。
resources:
- type: ELB
name: "hscale-elb"
selector:
names: ["tk-elb"]
resources:
- type: ServerGroup
name: "hscale-group" #サーバのプリフィックスにもなります
zone: "tk1b"
min_size: 2
max_size: 5
shutdown_force: false
plans:
- name: smallest
size: 2
- name: medium
size: 3
- name: largest
size: 5
template:
# tags: [ "tag1", "tag2" ]
description: "hscale-group"
interface_driver: "virtio"
plan:
core: 1
memory: 1
dedicated_cpu: false
network_interfaces:
- upstream: "shared" # 共有セグメント
expose:
ports: [80] #エンハンスドLBで使われるport番号
server_group_name: "gr1" #エンハンスドLBで使われるグループ名
disks:
- os_type: "almalinux"
plan: "ssd"
connection: "virtio"
size: 20
edit_parameter:
disabled: false
password: ""
disable_pw_auth: true
enable_dhcp: false
change_partition_uuid: true
ssh_keys:
- "ssh-ed25519 **********"
startup_scripts:
- |
#!/bin/bash
sudo yum install -y nginx
sudo systemctl enable nginx
echo -e "keepalive_requests 10;\ngzip_proxied any;\ngzip on;\ngzip_http_version 1.0;\ngzip_comp_level 9;\ngzip_types text/html;" > /etc/nginx/conf.d/gzip.conf
curl https://ja.wikipedia.org/wiki/%E4%B8%96%E7%95%8C%E9%81%BA%E7%94%A3 > /usr/share/nginx/html/sekai.html
sudo systemctl start nginx
echo "server name: {{ .Name }}" > /usr/share/nginx/html/index.html
echo "OK" > /usr/share/nginx/html/live
firewall-cmd --permanent --add-service http
firewall-cmd --reload
# オートスケーラーの動作設定
autoscaler:
cooldown: 540 # ジョブの連続実行を抑止するためのクールダウン期間を秒数で指定。デフォルト: 600(10分)
ほぼ同じですが、nginxに負荷をかけるため大きめのHTMLとgzipの設定を追加しています。
アクティビティグラフの情報取得
アクティビティグラフは、コントールパネルにも表示されています。5分ごとにCPUやトラフィック情報を収集し、表示しています。データはAPIでも取得可能です。

アクティビティグラフのデータからオートスケールを簡単に実現できるよう、名前が指定したprefixのサーバ群のCPU使用率を取得し、コア数でCPU_TIMEを割り、最大・最小・平均のCPU使用率を出力するコマンドを新たに作りました。
実行例すると以下のように表示されます。さくらのクラウドのAPIを呼び出すためのTOKENなどは --env-from で指定したファイルから読み出せるようにしてあります。autoscalerの設定時に /etc/autoscaler/core.config にTOKENを書いているのでそれを利用します。
$ /usr/local/bin/sacloud-cpu-usage --env-from /etc/autoscaler/core.config --zone tk1b --prefix hscale-group --time 2
2021/09/24 17:11:15 hscale-group-001 cores:1 cpu:0.036667 time:2021-09-24 17:00:00 +0900 JST
2021/09/24 17:11:15 hscale-group-001 cores:1 cpu:0.033333 time:2021-09-24 17:05:00 +0900 JST
2021/09/24 17:11:15 hscale-group-001 avg:3.500000
2021/09/24 17:11:15 hscale-group-002 cores:1 cpu:0.033333 time:2021-09-24 17:00:00 +0900 JST
2021/09/24 17:11:15 hscale-group-002 cores:1 cpu:0.033333 time:2021-09-24 17:05:00 +0900 JST
2021/09/24 17:11:15 hscale-group-002 avg:3.333333
{"75pt":3.5000000000000004,"90pt":3.5000000000000004,"95pt":3.5000000000000004,"99pt":3.5000000000000004,\
"avg":3.4166666666500003,"max":3.5000000000000004,"min":3.3333333333,"servers":[{"avg":3.5000000000000004,\
"cores":1,"monitors":[{"cpu_time":0.036666666667,"time":"2021-09-24 17:00:00 +0900 JST"},{"cpu_time":0.033333333333,\
"time":"2021-09-24 17:05:00 +0900 JST"}],"name":"hscale-group-001"},{"avg":3.3333333333,"cores":1,"monitors":\
[{"cpu_time":0.033333333333"time":"2021-09-24 17:00:00 +0900 JST"},{"cpu_time":0.033333333333,"time":\
"2021-09-24 17:05:00 +0900 JST"}],"name":"hscale-group-002"}]}
標準の出力はJSON形式でされますが、—query オプションで jq のシンタックスで表示するデータを絞ることができます。
$ /usr/local/bin/sacloud-cpu-usage --env-from /etc/autoscaler/core.config --zone tk1b --prefix hscale-group --time 1 --query '.avg|round' 2021/09/24 17:12:52 hscale-group-001 cores:1 cpu:0.033333 time:2021-09-24 17:10:00 +0900 JST 2021/09/24 17:12:52 hscale-group-001 avg:3.333333 2021/09/24 17:12:53 hscale-group-002 cores:1 cpu:0.033333 time:2021-09-24 17:10:00 +0900 JST 2021/09/24 17:12:53 hscale-group-002 avg:3.333333 3
testコマンドでの評価は、floatを扱えないので、jqの round 関数で四捨五入してます。このqueryの処理にはgojqを使ってます。ライブラリ的にも使えて最高便利です!
オートスケールのcronの設置から最初のサーバの起動
sacloud-cpu-usage を使ったshell scriptを書きます
#!/bin/bash
set -e
cpu_usage=$(/usr/local/bin/sacloud-cpu-usage --env-from /etc/autoscaler/core.config --zone tk1b --prefix hscale-group --time 1 --query '.avg|round')
if [ $cpu_usage -gt 50 ]; then
echo "Scale up"
/usr/local/sbin/autoscaler inputs direct up --dest unix:/var/run/autoscaler/autoscaler.sock --resource-name hscale-group
elif [ $cpu_usage -lt 20 -a $cpu_usage -gt 1]; then
echo "Scale down"
/usr/local/sbin/autoscaler inputs direct down --dest unix:/var/run/autoscaler/autoscaler.sock --resource-name hscale-group
else
echo "Keep"
/usr/local/sbin/autoscaler inputs direct up --dest unix:/var/run/autoscaler/autoscaler.sock --desired-state-name smallest --resource-name hscale-group
fi
sacloud-cpu-usageとgojqのおかげですごく簡単になりました。
そしてcronで起動します。
SHELL=/bin/bash */2 * * * * bash /etc/autoscaler/autoscale.sh |& logger -t autoscale
コマンドの出力を syslogに送るため、|& logger をコマンドの後ろに付けています。SHELL にてbashを指定しているのは、autoscalerを実行しているサーバがubuntuなのでデフォルトシェルがdashとなり、そのままでは |& が利用できないからです。
初回起動時、サーバなければ、最後の else 句にあるコマンドからサーバが作られます。
Sep 27 09:20:30 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:20:30+09:00 level=info message="autoscaler core started" address=/var/run/autoscale /autoscaler.sock
Sep 27 09:22:01 bastion1 autoscale: Keep
Sep 27 09:22:01 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:01+09:00 level=info request=Up message="request received"
Sep 27 09:22:01 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:01+09:00 level=info request=Up source=default resource=hscale-group status=JOB_ACCEPTED
Sep 27 09:22:01 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:01+09:00 level=info request=Up source=default resource=hscale-group status=JOB_RUNNING
Sep 27 09:22:01 bastion1 autoscale: status: JOB_ACCEPTED, job-id: hscale-group
Sep 27 09:22:02 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:02+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=ACCEPTED
Sep 27 09:22:02 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:02+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING
Sep 27 09:22:02 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:02+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log=creating...
Sep 27 09:22:04 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:04+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log="created: {ID:113301705264, Name:hscale-group-001}"
Sep 27 09:22:04 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:04+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log="creating disk[0]..."
Sep 27 09:23:12 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:23:12+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log="created disk[0]: {ID:113301705268, Name:hscale-group-001-disk001, ServerID:113301705264}"
Sep 27 09:23:12 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:23:12+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log=starting...
....
サーバが作られているところ

2台起動後、負荷がかかるまでは、elif [ $cpu_usage -lt 20 -a $cpu_usage -gt 1]; then の条件にマッチするためScale Downが実行されます。ただし、min_sizeが2台となっているため、これ以上サーバが削除されたりはしていません。
Sep 27 09:38:01 bastion1 autoscale: 2021/09/27 09:38:01 hscale-group-001 cores:1 cpu:0.030000 time:2021-09-27 09:35:00 +0900 JST Sep 27 09:38:01 bastion1 autoscale: 2021/09/27 09:38:01 hscale-group-001 avg:3.000000 Sep 27 09:38:02 bastion1 autoscale: 2021/09/27 09:38:02 hscale-group-002 cores:1 cpu:0.033333 time:2021-09-27 09:35:00 +0900 JST Sep 27 09:38:02 bastion1 autoscale: 2021/09/27 09:38:02 hscale-group-002 avg:3.333333 Sep 27 09:38:02 bastion1 autoscale: Scale down Sep 27 09:38:02 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:38:02+09:00 level=info request=Down message="request received" Sep 27 09:38:02 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:38:02+09:00 level=info request=Down source=default resource=hscale-group status=JOB_ACCEPTED Sep 27 09:38:02 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:38:02+09:00 level=info request=Down source=default resource=hscale-group status=JOB_RUNNING Sep 27 09:38:02 bastion1 autoscale: status: JOB_ACCEPTED, job-id: hscale-group Sep 27 09:38:03 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:38:03+09:00 level=info request=Down source=default resource=hscale-group status=JOB_DONE Sep 27 09:40:02 bastion1 autoscale: 2021/09/27 09:40:02 hscale-group-001 cores:1 cpu:0.030000 time:2021-09-27 09:35:00 +0900 JST Sep 27 09:40:02 bastion1 autoscale: 2021/09/27 09:40:02 hscale-group-001 avg:3.000000 Sep 27 09:40:03 bastion1 autoscale: 2021/09/27 09:40:03 hscale-group-002 cores:1 cpu:0.033333 time:2021-09-27 09:35:00 +0900 JST Sep 27 09:40:03 bastion1 autoscale: 2021/09/27 09:40:03 hscale-group-002 avg:3.333333 Sep 27 09:40:03 bastion1 autoscale: Scale down Sep 27 09:40:03 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:40:03+09:00 level=info request=Down message="request received" Sep 27 09:40:03 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:40:03+09:00 level=info request=Down source=default resource=hscale-group status=JOB_IGNORED message="job is in an unacceptable state" Sep 27 09:40:03 bastion1 autoscale: status: JOB_DONE, job-id: hscale-group, message: job is in an unacceptable state
スケールアップの確認
別のサーバから ApacheBench でアクセス負荷をかけることで、オートスケールされるかを検証してみます。
ApacheBench の実行
$ watch "ab -k -H 'Accept-Encoding: deflate, gzip, br' -c 3 -t 600 http://tk-elb.kazeburo.work/sekai.html"
アクティビティグラフで負荷が上がってきているのが確認できます。
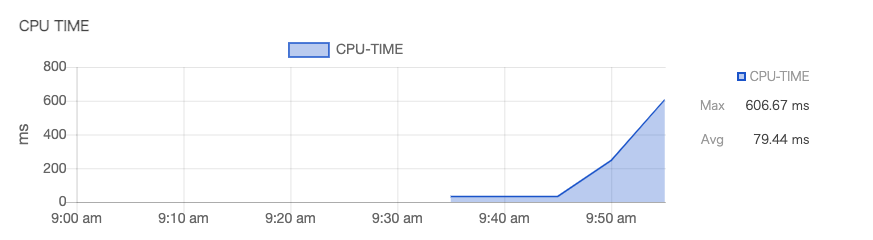
そしてcronからもCPU負荷が上がっているのが検知され、オートスケールが開始されます。
Sep 27 10:00:01 bastion1 autoscale: 2021/09/27 10:00:01 hscale-group-001 cores:1 cpu:0.606667 time:2021-09-27 09:55:00 +0900 JST Sep 27 10:00:01 bastion1 autoscale: 2021/09/27 10:00:01 hscale-group-001 avg:60.666667 Sep 27 10:00:02 bastion1 autoscale: 2021/09/27 10:00:02 hscale-group-002 cores:1 cpu:0.606667 time:2021-09-27 09:55:00 +0900 JST Sep 27 10:00:02 bastion1 autoscale: 2021/09/27 10:00:02 hscale-group-002 avg:60.666667 Sep 27 10:00:02 bastion1 autoscale: Scale up Sep 27 10:00:02 bastion1 autoscaler[691943]: timestamp=2021-09-27T10:00:02+09:00 level=info request=Up message="request received" Sep 27 10:00:02 bastion1 autoscaler[691943]: timestamp=2021-09-27T10:00:02+09:00 level=info request=Up source=default resource=hscale-group status=JOB_ACCEPTED Sep 27 10:00:02 bastion1 autoscaler[691943]: timestamp=2021-09-27T10:00:02+09:00 level=info request=Up source=default resource=hscale-group status=JOB_RUNNING Sep 27 10:00:02 bastion1 autoscale: status: JOB_ACCEPTED, job-id: hscale-group Sep 27 10:00:04 bastion1 autoscaler[691943]: timestamp=2021-09-27T10:00:04+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-003 step=Handle handler=server-horizontal-scaler status=ACCEPTED Sep 27 10:00:04 bastion1 autoscaler[691943]: timestamp=2021-09-27T10:00:04+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-003 step=Handle handler=server-horizontal-scaler status=RUNNING Sep 27 10:00:04 bastion1 autoscaler[691943]: timestamp=2021-09-27T10:00:04+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-003 step=Handle handler=server-horizontal-scaler status=RUNNING log=creating...
ApacheBenchを止めると、CPU負荷が納まりScale Downされます。
まとめ
sacloud/autoscaler とアクティビティグラフのデータを用いたオートスケールが実現できました。アクティビティグラフを利用することで、監視ツールなどを別途用意する必要がなくなり、オートスケールを楽に導入することができそうです。
ISUCON 11本選に「チーム中目黒乗り過ごし」で参加して、結果はFailでした
結果はこちら
ISUCON11本選にhanabokuro氏、mtokioka氏と参加して、結果はFailで失格となりました。スコア的には5位ぐらいかなと
去年も本選Failなので、2年連続本選でスコア残せませんでした。難しい。
なかなか厳しい問題でしたが、ベンチマークの実行やサーバ環境は快適で、集中して取り組むことはできました。出題の皆様、運営の皆様ありがとうございます。
やったこと
チーム紹介スライドつくりました。おじさんむけ旅雑誌ぽくしてみた

スコアの履歴はこのようになりました、

スコアが伸びない時間がながく、Failも多くありました。
Repositoryはこちらで公開しております
PRつくってマージするスタイルでやっておりましたが、最終的にマージしたPRが38個、マージしてないPRが3個となりました。 うちRevertのPRが7個です。ベンチマークの不整合チェックに引っ掛かり、ブランチで作業し、戻したものもたくさんあります。
最終的にサーバ3台
として利用しました。MySQLの負荷がどうしても下がらず、レプリケーションを行ったのですが、利用できる箇所は本当に少なく、不安定になってしまい、戦略ミスでした。
そのほか、zipを作成ところにhard link(os.Link)を利用し、圧縮率を -1にしたり、singleflightおよびsync.WaitGroupを使ったSQLの並列実行の制御、不必要だったトランザクションの削除などを行いましたが、やっぱり厳しい感じでした。
機会があれば、出せなかったGetGradesのクエリ改善を試したり、業務ではもう何年も使ってない外部キーが性能にどう影響したのか調査をしてみたい。
最後に
今回、事前にインタビュー記事などに載せていただりしました。ありがとうございます。
学生が強くなり、我々は勝つのが難しいのではないか(これも素晴らしいことです)ということも言われておりましたが、今回はfujiwara組の優勝(おめでとうございます!!)と我々平均年齢45歳オーバーのチームでも本選出場とここまではできたので、定年を乗り過ごしてもう少し頑張っていけるのではいかと思います。
今は燃え尽きておりますが、ISUCONが来年も様々な背景をもつ多くのエンジニアと競いあえる場所として開かれ、また挑戦できるといいなと思ってます。
ISUCON11予選に「チーム中目黒乗り過ごし」で参加し本選出場決まりました
ISUCON11の予選に参加し、なんとか本選出場を決めました!チームは去年と同じ「中目黒乗り過ごし」でメンバーも変わらず、hanabokuro氏、mtokioka氏と参加しました。
チーム中目黒乗り過ごしとして、2年連続で9位で本選出場です。去年の予選記事はこちら。
ちなみに、去年の本選はFailでした。
先日ISUCONのインタビュー記事に載りましたので、こちらもどうぞ
今回の問題

ISUのコンディションを収集し、可視化するサイトということで、IoTや大量のネットワーク機器の監視メトリクスの扱いが課題のネタとなっていたように思いました。
世界観が面白く、ISUが投擲の道具じゃなく、愛される存在になったのだと感慨深いものがありました。
構成とスコア
当初は1台でやっておりましたが、最終的に3台を次のように使いました。

getTrendの生成負荷が高かったので、nginxとgetTrendだけを処理するappを用意し、その他を別のappに寄せました。
スコアはこんな感じで推移。

ベストスコアは 684,624 ですが最終的には 289,148 でした。
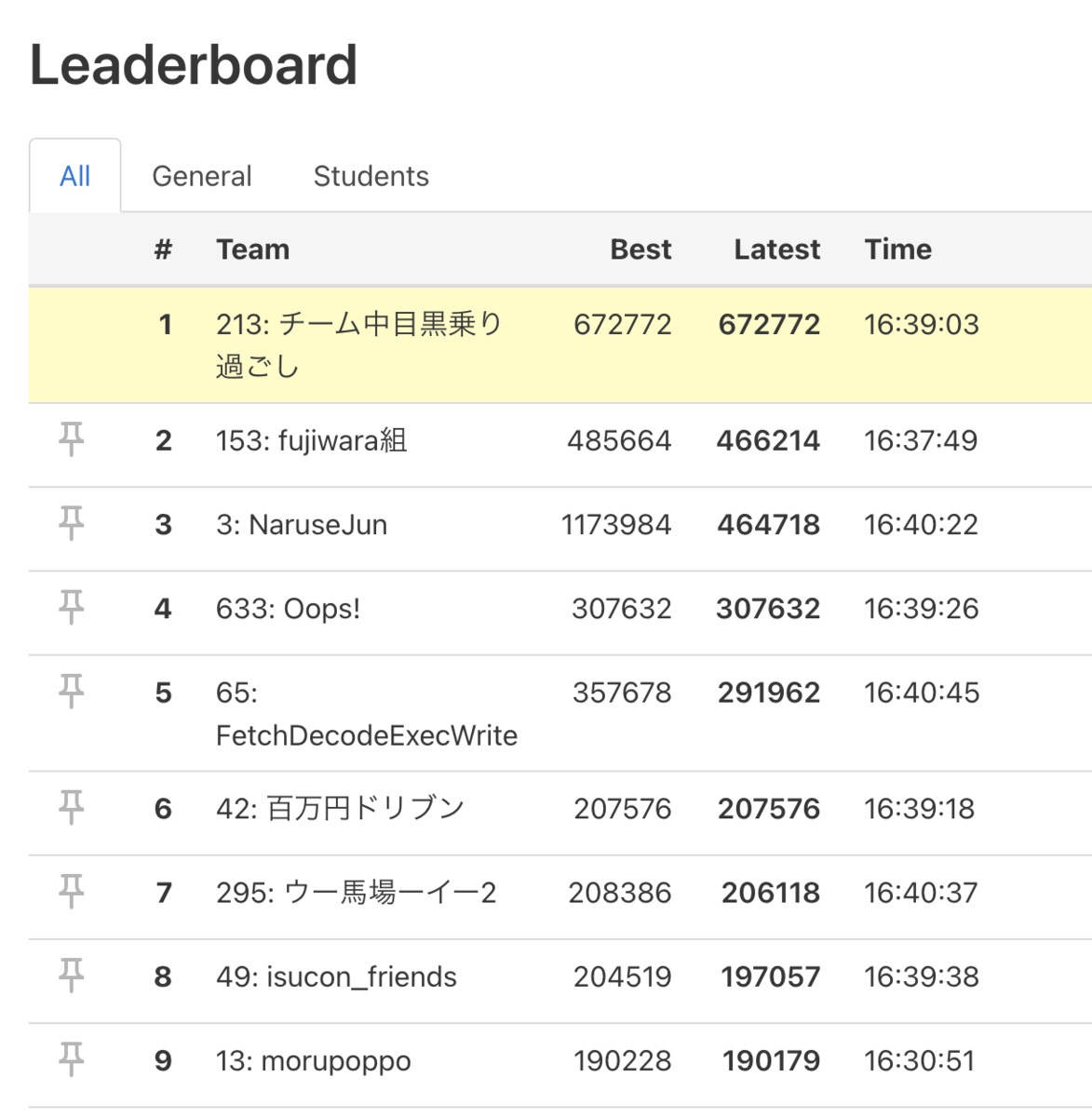
17時の時点では、トップでしたのでパブリックスコアボードでしばらく1位でした。ちょっとうれしい。
使ったツール・言語
DBのクエリの分析に、pt-query-digest を使い、アプリケーションの方にはGCPの Cloud Profiler をいれてどこに時間がかかっていそうかを見ていました。
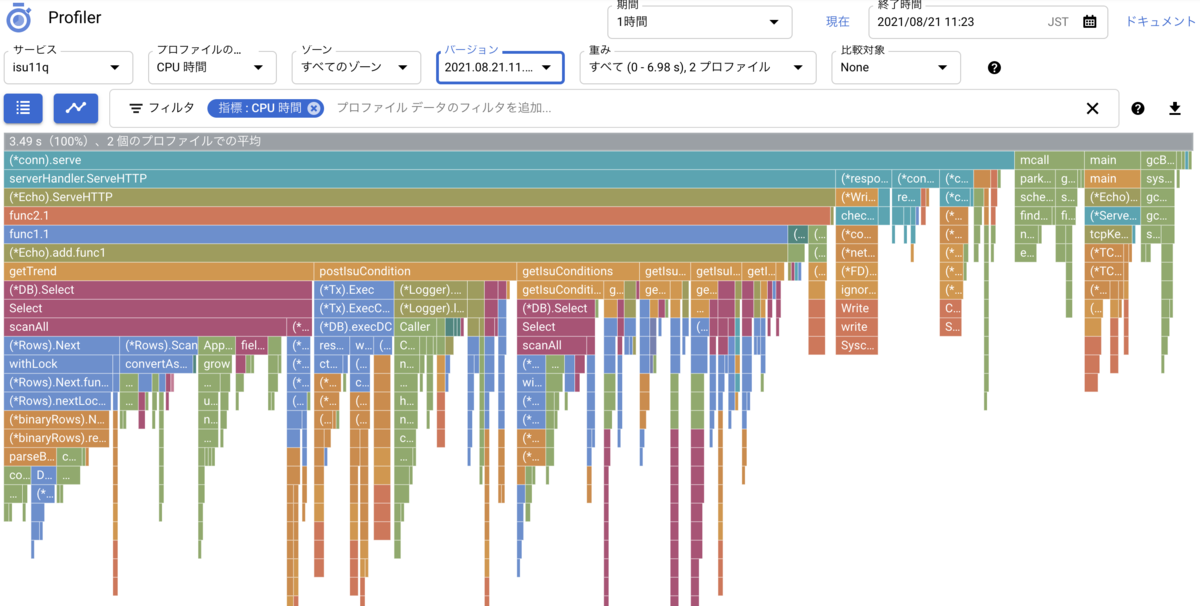
これは 11:20ごろのprofileのスクリーンショットです。
言語は Go になります。わかりにくいところは Perl も参考にさせていただきました!
やったこと
使った repository はここで公開しています
前半
まずtopをみて、DBの負荷が目立ち、INSERTも多くあることがわかったので、MariaDBの設定を行いました。MySQLではなかったのは一瞬悩みましたがそのままにしています。。
sync_binlog = 0 innodb_doublewrite = 0 innodb_flush_log_at_trx_commit = 2 innodb_flush_method = O_DIRECT_NO_FSYNC innodb_adaptive_hash_index = 0
複数台にする際にbind-addressを消した以外はいれたのはこれだけです。
そして、getTrendの生成をbackgroudに回したり、icon画像が不要なところではselectしないようにしたり、必要なindexを張ったりしていたのが序盤です。スコアは2万を超えたあたり。
中盤 (13時すぎ)
Goのapplicationはアクセスログを吐くようになっていて、syslogに負荷がかかり、またログが見づらくなるので、ログのミドルウェアを外しつつdebugモードも解除。
さらに1台ではスコア向上が難しいと考え、複数台構成に変更し、このタイミングでデプロイを簡単にするMakefileを作りました。
この時間帯には、getIsuConditionsFromDB の負荷を下げるため、isu_condition テーブルに condition_level カラムを追加した。
スコアは 10万近くまで上昇。
終盤 (15時すぎ)
捨てるデータの割合であるdropProbabilityを0.5まで下げてスコアが上がるのを確認。
generateIsuGraphResponse でDBからデータを取ってくるところにBETWEENを入れ、不要なデータを取得しないよう対応し、getIsuListのN+1を解消、getTrendにLIMIT 1を追加するなどして、16:50ぐらいには、dropProbabilityをもっと下げて、ベストスコアの68万点がでた。
途中中断
17時ちょっと過ぎたところで、スコアがぐっと下がってしまい 26万点となってしまう。この理由が分かっていない状態で、中断となったのが我々には痛かった。中断の間は、kernelパラメータいれたり、再起動の試験をして過ごす。
再開後、applicationのmax file descriptorに引っかかっているがわかったので、それをいれてみるなどしたが、スコアは戻らず、最終スコアは32万点でおわり、あとはFailしていないことだけを祈る形となった。
まとめ
Failせず、本選出場できるスコアが出せたのは嬉しい。中断前のスコアがなぜ出せなかったのかは、今後の課題としたい。
今回の問題、ぱっと見シンプルなようで、ボトルネックが変わっていくところなど、奥が深いように感じました。加点ルールをより生かせれば、もっと高いスコアが出せるような気がするので、時間があるときに挑戦したいと思います。
また、環境構築、ベンチマーカやポータルも丁寧に作られており、競技に集中できるようなっておりました。おそらく準備は大変だったと思います。運営のみなさまありがとうございました。本選も楽しみです。よろしくお願いします。
今回、ちょうど17時にトップに立てたので、家族にはいいところを見せられたようです。いつも応援ありがとー。本選もFailしないよう頑張ります。
さくらインターネットの新PaaSの「Hacobune」で phpMyAdmin と WordPress を動かす
昨日オープンベータが開始されたさくらインターネットの新しいPaaS、DockerイメージやGitHubとの連携することで、インフラにとらわれることなく、アプリケーションのデプロイができるようになっています。データベースや永続ボリュームがすでにサポートされ、今後、WebサービスやSaaSの基盤として、またチームでの開発に適した機能が拡充されていく予定です。
さっそく試していただき、記事を書いていただいています。ありがとうございます。
この記事ではサンプルのアプリケーションとして、MySQLアドオンを使い phpMyAdminとWordPress を立ち上げてみます。
プロジェクトの作成
さくらのクラウドのホームからHacobuneのコンソールへ移動し、新しいプロジェクトを作ります。

ここでは名前は hacopress としました。
Read moresacloud/autoscaler でさくらのクラウドの水平スケールを試す
さくらのクラウドでオートスケールを実現する sacloud/autoscaler が v0.1.0 で水平スケールに対応したので試してみます。
yamamoto_febc さんのさくらのイベントでの発表資料はこちら
sacloud/autoscalerの構成を知るためにはこの資料を最初に目を通すのをお勧めします。
またv0.1.0 以前からサポートしている垂直スケールにつてはこちらの記事もわかりやすいです!
とりあえず、今回の水平スケールは、サーバの増減とエンハンスドLBにサーバを参加させるところまでを試しました。
準備
サーバを2台とエンハンスドLBを作っておきます。
まず、autoscalerを動かすサーバを作成します。
名前: autoscale1 プラン: 1Core-1GB #最小 NIC: 共有セグメント OS: AlmaLinux 8.4
設定はあとでやります。
次に、エンハンスドLBに参加させるサーバを作成。
名前: base1 プラン: 1Core-1GB #最小 NIC: 共有セグメント OS: AlmaLinux 8.4
このサーバの名前を、下でオートスケールするサーバグループの名前から始まるように設定すると、オートスケールの管理下に置かれ、スケールダウンした際にサーバが削除される可能性があります。
サーバが起動したら、テスト用のnginxをいれておきます
sudo yum install -y nginx sudo systemctl enable nginx sudo systemctl start nginx echo "server name: $(hostname)" | sudo tee /usr/share/nginx/html/index.html echo "OK" | sudo tee /usr/share/nginx/html/live sudo firewall-cmd --permanent --add-service http sudo firewall-cmd --reload
エンハンスドLBを作成し、実サーバとして base1 を追加(サーバグループは gr1 とします)。またproxyされるようルールもつくります。


curlでも動作を確認
% curl https://example.com/ server name: base1
salcoud/autoscalerのセットアップ
まずダウンロードして所定の場所に設置
wget https://github.com/sacloud/autoscaler/releases/download/v0.1.0/autoscaler_linux-amd64.zip unzip autoscaler_linux-amd64.zip autoscaler sudo install autoscaler /usr/local/sbin
systemdのunitファイルもダウンロードして、/etc/systemd/system以下にコピーします。
wget https://raw.githubusercontent.com/sacloud/autoscaler/main/examples/systemd/autoscaler_core.service sudo cp autoscaler_core.service /etc/systemd/system/
次に、autoscaler coreの実行ユーザを作成し、必要なディレクトリを作っておきます
sudo useradd -s /sbin/nologin -M autoscaler sudo mkdir -p /etc/autoscaler sudo mkdir -p /var/run/autoscaler sudo chgrp autoscaler /var/run/autoscaler/ sudo chmod 770 /var/run/autoscaler/
また、autoscaler coreサーバの起動時の環境変数を設定するファイルを /etc/autoscaler/core.config に作ります。
$ cat /etc/autoscaler/core.config OPTIONS="--addr unix:/var/run/autoscaler/autoscaler.sock --config /etc/autoscaler/autoscaler.yaml --log-level info" SAKURACLOUD_ACCESS_TOKEN="" SAKURACLOUD_ACCESS_TOKEN_SECRET=""
TOKEN, SECRETはさくらのクラウドのコントロールパネルから作成して設定してください。
さて、最後にオートスケールに関する設定をします。今回は以下のようにしました。
resources:
- type: ELB
name: "hscale-elb"
selector:
names: ["tk-elb"] #エンハンスドLBに設定した名前
resources:
- type: ServerGroup
name: "hscale-group" #サーバのプリフィックスにもなります
zone: "tk1a"
min_size: 2
max_size: 5
shutdown_force: false
plans:
- name: smallest
size: 2
- name: medium
size: 3
- name: largest
size: 5
template:
description: "hscale-group"
interface_driver: "virtio"
plan:
core: 1
memory: 1
dedicated_cpu: false
network_interfaces:
- upstream: "shared" # 共有セグメント
expose:
ports: [80] #エンハンスドLBで使われるport番号
server_group_name: "gr1" #エンハンスドLBで使われるグループ名
disks:
- os_type: "almalinux"
plan: "ssd"
connection: "virtio"
size: 20
edit_parameter:
disabled: false
password: ""
disable_pw_auth: true
enable_dhcp: false
change_partition_uuid: true
ssh_keys:
- "ssh-ed25519 …." # サーバにログインするためのssh鍵
startup_scripts:
- |
#!/bin/bash
sudo yum install -y nginx
sudo systemctl enable nginx
sudo systemctl start nginx
echo "server name: {{ .Name }}" > /usr/share/nginx/html/index.html
echo "OK" > /usr/share/nginx/html/live
firewall-cmd --permanent --add-service http
firewall-cmd --reload
# オートスケーラーの動作設定
autoscaler:
cooldown: 180 # ジョブの連続実行を抑止するためのクールダウン期間を秒数で指定。デフォルト: 600(10分)
このファイルを /etc/autoscaler/autoscaler.yaml におきます
おいたら、autoscaler coreを起動します
sudo systemctl enable autoscaler_core.service sudo systemctl start autoscaler_core.service sudo systemctl status autoscaler_core.service
うまく動かない場合はstatusやログを確認するとよいでしょう
sudo journalctl -f -u autoscaler_*
オートスケールの検証
さっそく、スケールアップしてみましょう。
v0.1.0では対象のサーバが一台もないときに、スケールアップができない問題があるので desired-state-name をつけて、スケールアップをします。
コマンドは次のようになります。
$ sudo autoscaler inputs direct up --dest unix:/var/run/autoscaler/autoscaler.sock --desired-state-name smallest --resource-name hscale-group status: JOB_ACCEPTED, job-id: hscale-group
リソースとして、サーバグループの指定も必要です。 smallestの状態にするため、2台サーバが作成されていきます。
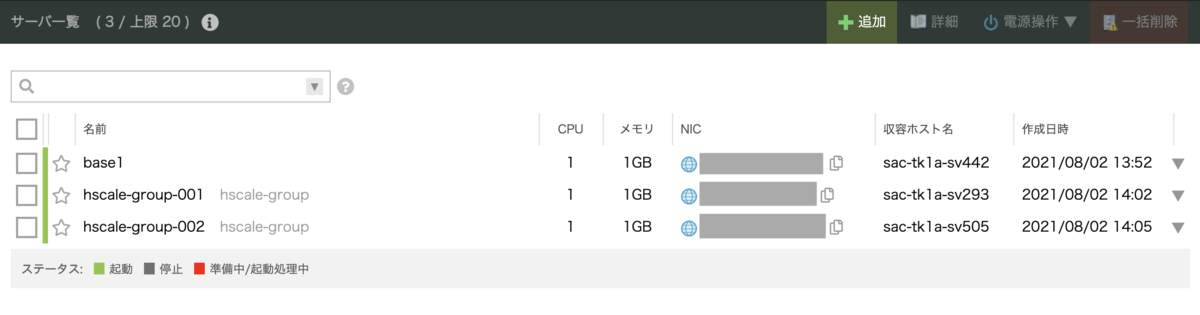
ロードバランサーにも追加されています

autoscalerのログでも作成の様子が確認できます。
Aug 02 14:01:45 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:45+09:00 level=info message="autoscaler core started" address=/var/run/autoscaler/autoscaler.sock
Aug 02 14:01:59 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:59+09:00 level=info request=Up message="request received"
Aug 02 14:01:59 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:59+09:00 level=info request=Up source=default resource=hscale-group status=JOB_ACCEPTED
Aug 02 14:01:59 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:59+09:00 level=info request=Up source=default resource=hscale-group status=JOB_RUNNING
Aug 02 14:01:59 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:59+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=ACCEPTED
Aug 02 14:01:59 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:59+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING
Aug 02 14:01:59 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:59+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log=creating...
Aug 02 14:02:06 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:02:06+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log="created: {ID:113301403488, Name:hscale-group-001}"
Aug 02 14:02:06 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:02:06+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log="creating disk[0]..."
Aug 02 14:04:46 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:04:46+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log="created disk[0]: {ID:113301403491, Name:hscale-group-001-disk001, ServerID:113301403488}"
Aug 02 14:04:46 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:04:46+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log=starting...
Aug 02 14:05:35 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:05:35+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=DONE log=started
Aug 02 14:05:35 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:05:35+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id=113301403488 name=hscale-group-001 step=PostHandle handler=elb-servers-handler status=ACCEPTED
… 中略 …
Aug 02 14:09:13 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:09:13+09:00 level=info request=Up source=default resource=hscale-group status=JOB_DONE
ここからさらにスケールアップするときは、
sudo autoscaler inputs direct up --dest unix:/var/run/autoscaler/autoscaler.sock --resource-name hscale-group
スケールダウンする時は、
sudo autoscaler inputs direct down --dest unix:/var/run/autoscaler/autoscaler.sock --resource-name hscale-group
となります。
autoscaler coreの設定時に指定した通り、一度スケールアップ・ダウンをしてから cooldownの 180秒はコマンドを受け付けません。コマンドの結果は次のようになりました。
$ sudo autoscaler inputs direct up --dest unix:/var/run/autoscaler/autoscaler.sock --resource-name hscale-group status: JOB_DONE, job-id: hscale-group, message: job is in an unacceptable state $ echo $? 0
まとめ
sacloud/autoscalerではprometheusなどからwebhookを受け取ってスケールアップ・ダウンするサーバを起動できたりするので、監視ツールが整備されている場合、そこからのwebhookを受け取ってスケールアップやスケールアウトが実現できそう。それ以外でも今回使ったCLIツールをcronなどで実行することで、時間帯に合わせてサーバを増減させたり、必要なサーバ台数をキープすることもできそうです。
うまく使えると運用が楽できそうー