sacloud/autoscaler とさくらのクラウドのアクティビティグラフで実現するオートスケール
前回の続きになります。
前回は autoscaler のコアサーバを起動し、cliからサーバの台数を増減させる水平スケールを試しました。今回はさくらのクラウドに備わるアクティビティグラフの情報を使い、自動でスケールアウト・インを行うオートスケールを試します。
設定
2022/3/4 追記
autoscaler v0.5.0 からコマンド体系および、設定が変更になっています。 以下のgistに動作確認した設定ファイルを置いています
autoscalerのインストールおよび基本的な設定は前回の記事を参考にしてください。 autoscaler_coreの設定は以下のようにしました。
resources:
- type: ELB
name: "hscale-elb"
selector:
names: ["tk-elb"]
resources:
- type: ServerGroup
name: "hscale-group" #サーバのプリフィックスにもなります
zone: "tk1b"
min_size: 2
max_size: 5
shutdown_force: false
plans:
- name: smallest
size: 2
- name: medium
size: 3
- name: largest
size: 5
template:
# tags: [ "tag1", "tag2" ]
description: "hscale-group"
interface_driver: "virtio"
plan:
core: 1
memory: 1
dedicated_cpu: false
network_interfaces:
- upstream: "shared" # 共有セグメント
expose:
ports: [80] #エンハンスドLBで使われるport番号
server_group_name: "gr1" #エンハンスドLBで使われるグループ名
disks:
- os_type: "almalinux"
plan: "ssd"
connection: "virtio"
size: 20
edit_parameter:
disabled: false
password: ""
disable_pw_auth: true
enable_dhcp: false
change_partition_uuid: true
ssh_keys:
- "ssh-ed25519 **********"
startup_scripts:
- |
#!/bin/bash
sudo yum install -y nginx
sudo systemctl enable nginx
echo -e "keepalive_requests 10;\ngzip_proxied any;\ngzip on;\ngzip_http_version 1.0;\ngzip_comp_level 9;\ngzip_types text/html;" > /etc/nginx/conf.d/gzip.conf
curl https://ja.wikipedia.org/wiki/%E4%B8%96%E7%95%8C%E9%81%BA%E7%94%A3 > /usr/share/nginx/html/sekai.html
sudo systemctl start nginx
echo "server name: {{ .Name }}" > /usr/share/nginx/html/index.html
echo "OK" > /usr/share/nginx/html/live
firewall-cmd --permanent --add-service http
firewall-cmd --reload
# オートスケーラーの動作設定
autoscaler:
cooldown: 540 # ジョブの連続実行を抑止するためのクールダウン期間を秒数で指定。デフォルト: 600(10分)
ほぼ同じですが、nginxに負荷をかけるため大きめのHTMLとgzipの設定を追加しています。
アクティビティグラフの情報取得
アクティビティグラフは、コントールパネルにも表示されています。5分ごとにCPUやトラフィック情報を収集し、表示しています。データはAPIでも取得可能です。

アクティビティグラフのデータからオートスケールを簡単に実現できるよう、名前が指定したprefixのサーバ群のCPU使用率を取得し、コア数でCPU_TIMEを割り、最大・最小・平均のCPU使用率を出力するコマンドを新たに作りました。
実行例すると以下のように表示されます。さくらのクラウドのAPIを呼び出すためのTOKENなどは --env-from で指定したファイルから読み出せるようにしてあります。autoscalerの設定時に /etc/autoscaler/core.config にTOKENを書いているのでそれを利用します。
$ /usr/local/bin/sacloud-cpu-usage --env-from /etc/autoscaler/core.config --zone tk1b --prefix hscale-group --time 2
2021/09/24 17:11:15 hscale-group-001 cores:1 cpu:0.036667 time:2021-09-24 17:00:00 +0900 JST
2021/09/24 17:11:15 hscale-group-001 cores:1 cpu:0.033333 time:2021-09-24 17:05:00 +0900 JST
2021/09/24 17:11:15 hscale-group-001 avg:3.500000
2021/09/24 17:11:15 hscale-group-002 cores:1 cpu:0.033333 time:2021-09-24 17:00:00 +0900 JST
2021/09/24 17:11:15 hscale-group-002 cores:1 cpu:0.033333 time:2021-09-24 17:05:00 +0900 JST
2021/09/24 17:11:15 hscale-group-002 avg:3.333333
{"75pt":3.5000000000000004,"90pt":3.5000000000000004,"95pt":3.5000000000000004,"99pt":3.5000000000000004,\
"avg":3.4166666666500003,"max":3.5000000000000004,"min":3.3333333333,"servers":[{"avg":3.5000000000000004,\
"cores":1,"monitors":[{"cpu_time":0.036666666667,"time":"2021-09-24 17:00:00 +0900 JST"},{"cpu_time":0.033333333333,\
"time":"2021-09-24 17:05:00 +0900 JST"}],"name":"hscale-group-001"},{"avg":3.3333333333,"cores":1,"monitors":\
[{"cpu_time":0.033333333333"time":"2021-09-24 17:00:00 +0900 JST"},{"cpu_time":0.033333333333,"time":\
"2021-09-24 17:05:00 +0900 JST"}],"name":"hscale-group-002"}]}
標準の出力はJSON形式でされますが、—query オプションで jq のシンタックスで表示するデータを絞ることができます。
$ /usr/local/bin/sacloud-cpu-usage --env-from /etc/autoscaler/core.config --zone tk1b --prefix hscale-group --time 1 --query '.avg|round' 2021/09/24 17:12:52 hscale-group-001 cores:1 cpu:0.033333 time:2021-09-24 17:10:00 +0900 JST 2021/09/24 17:12:52 hscale-group-001 avg:3.333333 2021/09/24 17:12:53 hscale-group-002 cores:1 cpu:0.033333 time:2021-09-24 17:10:00 +0900 JST 2021/09/24 17:12:53 hscale-group-002 avg:3.333333 3
testコマンドでの評価は、floatを扱えないので、jqの round 関数で四捨五入してます。このqueryの処理にはgojqを使ってます。ライブラリ的にも使えて最高便利です!
オートスケールのcronの設置から最初のサーバの起動
sacloud-cpu-usage を使ったshell scriptを書きます
#!/bin/bash
set -e
cpu_usage=$(/usr/local/bin/sacloud-cpu-usage --env-from /etc/autoscaler/core.config --zone tk1b --prefix hscale-group --time 1 --query '.avg|round')
if [ $cpu_usage -gt 50 ]; then
echo "Scale up"
/usr/local/sbin/autoscaler inputs direct up --dest unix:/var/run/autoscaler/autoscaler.sock --resource-name hscale-group
elif [ $cpu_usage -lt 20 -a $cpu_usage -gt 1]; then
echo "Scale down"
/usr/local/sbin/autoscaler inputs direct down --dest unix:/var/run/autoscaler/autoscaler.sock --resource-name hscale-group
else
echo "Keep"
/usr/local/sbin/autoscaler inputs direct up --dest unix:/var/run/autoscaler/autoscaler.sock --desired-state-name smallest --resource-name hscale-group
fi
sacloud-cpu-usageとgojqのおかげですごく簡単になりました。
そしてcronで起動します。
SHELL=/bin/bash */2 * * * * bash /etc/autoscaler/autoscale.sh |& logger -t autoscale
コマンドの出力を syslogに送るため、|& logger をコマンドの後ろに付けています。SHELL にてbashを指定しているのは、autoscalerを実行しているサーバがubuntuなのでデフォルトシェルがdashとなり、そのままでは |& が利用できないからです。
初回起動時、サーバなければ、最後の else 句にあるコマンドからサーバが作られます。
Sep 27 09:20:30 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:20:30+09:00 level=info message="autoscaler core started" address=/var/run/autoscale /autoscaler.sock
Sep 27 09:22:01 bastion1 autoscale: Keep
Sep 27 09:22:01 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:01+09:00 level=info request=Up message="request received"
Sep 27 09:22:01 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:01+09:00 level=info request=Up source=default resource=hscale-group status=JOB_ACCEPTED
Sep 27 09:22:01 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:01+09:00 level=info request=Up source=default resource=hscale-group status=JOB_RUNNING
Sep 27 09:22:01 bastion1 autoscale: status: JOB_ACCEPTED, job-id: hscale-group
Sep 27 09:22:02 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:02+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=ACCEPTED
Sep 27 09:22:02 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:02+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING
Sep 27 09:22:02 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:02+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log=creating...
Sep 27 09:22:04 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:04+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log="created: {ID:113301705264, Name:hscale-group-001}"
Sep 27 09:22:04 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:22:04+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log="creating disk[0]..."
Sep 27 09:23:12 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:23:12+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log="created disk[0]: {ID:113301705268, Name:hscale-group-001-disk001, ServerID:113301705264}"
Sep 27 09:23:12 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:23:12+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log=starting...
....
サーバが作られているところ

2台起動後、負荷がかかるまでは、elif [ $cpu_usage -lt 20 -a $cpu_usage -gt 1]; then の条件にマッチするためScale Downが実行されます。ただし、min_sizeが2台となっているため、これ以上サーバが削除されたりはしていません。
Sep 27 09:38:01 bastion1 autoscale: 2021/09/27 09:38:01 hscale-group-001 cores:1 cpu:0.030000 time:2021-09-27 09:35:00 +0900 JST Sep 27 09:38:01 bastion1 autoscale: 2021/09/27 09:38:01 hscale-group-001 avg:3.000000 Sep 27 09:38:02 bastion1 autoscale: 2021/09/27 09:38:02 hscale-group-002 cores:1 cpu:0.033333 time:2021-09-27 09:35:00 +0900 JST Sep 27 09:38:02 bastion1 autoscale: 2021/09/27 09:38:02 hscale-group-002 avg:3.333333 Sep 27 09:38:02 bastion1 autoscale: Scale down Sep 27 09:38:02 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:38:02+09:00 level=info request=Down message="request received" Sep 27 09:38:02 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:38:02+09:00 level=info request=Down source=default resource=hscale-group status=JOB_ACCEPTED Sep 27 09:38:02 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:38:02+09:00 level=info request=Down source=default resource=hscale-group status=JOB_RUNNING Sep 27 09:38:02 bastion1 autoscale: status: JOB_ACCEPTED, job-id: hscale-group Sep 27 09:38:03 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:38:03+09:00 level=info request=Down source=default resource=hscale-group status=JOB_DONE Sep 27 09:40:02 bastion1 autoscale: 2021/09/27 09:40:02 hscale-group-001 cores:1 cpu:0.030000 time:2021-09-27 09:35:00 +0900 JST Sep 27 09:40:02 bastion1 autoscale: 2021/09/27 09:40:02 hscale-group-001 avg:3.000000 Sep 27 09:40:03 bastion1 autoscale: 2021/09/27 09:40:03 hscale-group-002 cores:1 cpu:0.033333 time:2021-09-27 09:35:00 +0900 JST Sep 27 09:40:03 bastion1 autoscale: 2021/09/27 09:40:03 hscale-group-002 avg:3.333333 Sep 27 09:40:03 bastion1 autoscale: Scale down Sep 27 09:40:03 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:40:03+09:00 level=info request=Down message="request received" Sep 27 09:40:03 bastion1 autoscaler[691521]: timestamp=2021-09-27T09:40:03+09:00 level=info request=Down source=default resource=hscale-group status=JOB_IGNORED message="job is in an unacceptable state" Sep 27 09:40:03 bastion1 autoscale: status: JOB_DONE, job-id: hscale-group, message: job is in an unacceptable state
スケールアップの確認
別のサーバから ApacheBench でアクセス負荷をかけることで、オートスケールされるかを検証してみます。
ApacheBench の実行
$ watch "ab -k -H 'Accept-Encoding: deflate, gzip, br' -c 3 -t 600 http://tk-elb.kazeburo.work/sekai.html"
アクティビティグラフで負荷が上がってきているのが確認できます。
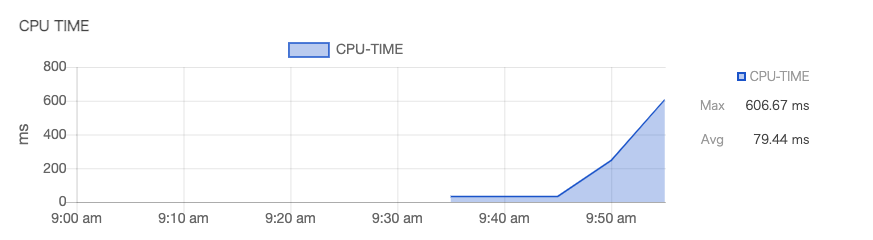
そしてcronからもCPU負荷が上がっているのが検知され、オートスケールが開始されます。
Sep 27 10:00:01 bastion1 autoscale: 2021/09/27 10:00:01 hscale-group-001 cores:1 cpu:0.606667 time:2021-09-27 09:55:00 +0900 JST Sep 27 10:00:01 bastion1 autoscale: 2021/09/27 10:00:01 hscale-group-001 avg:60.666667 Sep 27 10:00:02 bastion1 autoscale: 2021/09/27 10:00:02 hscale-group-002 cores:1 cpu:0.606667 time:2021-09-27 09:55:00 +0900 JST Sep 27 10:00:02 bastion1 autoscale: 2021/09/27 10:00:02 hscale-group-002 avg:60.666667 Sep 27 10:00:02 bastion1 autoscale: Scale up Sep 27 10:00:02 bastion1 autoscaler[691943]: timestamp=2021-09-27T10:00:02+09:00 level=info request=Up message="request received" Sep 27 10:00:02 bastion1 autoscaler[691943]: timestamp=2021-09-27T10:00:02+09:00 level=info request=Up source=default resource=hscale-group status=JOB_ACCEPTED Sep 27 10:00:02 bastion1 autoscaler[691943]: timestamp=2021-09-27T10:00:02+09:00 level=info request=Up source=default resource=hscale-group status=JOB_RUNNING Sep 27 10:00:02 bastion1 autoscale: status: JOB_ACCEPTED, job-id: hscale-group Sep 27 10:00:04 bastion1 autoscaler[691943]: timestamp=2021-09-27T10:00:04+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-003 step=Handle handler=server-horizontal-scaler status=ACCEPTED Sep 27 10:00:04 bastion1 autoscaler[691943]: timestamp=2021-09-27T10:00:04+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-003 step=Handle handler=server-horizontal-scaler status=RUNNING Sep 27 10:00:04 bastion1 autoscaler[691943]: timestamp=2021-09-27T10:00:04+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1b id="(known after handle)" name=hscale-group-003 step=Handle handler=server-horizontal-scaler status=RUNNING log=creating...
ApacheBenchを止めると、CPU負荷が納まりScale Downされます。
まとめ
sacloud/autoscaler とアクティビティグラフのデータを用いたオートスケールが実現できました。アクティビティグラフを利用することで、監視ツールなどを別途用意する必要がなくなり、オートスケールを楽に導入することができそうです。
ISUCON 11本選に「チーム中目黒乗り過ごし」で参加して、結果はFailでした
結果はこちら
ISUCON11本選にhanabokuro氏、mtokioka氏と参加して、結果はFailで失格となりました。スコア的には5位ぐらいかなと
去年も本選Failなので、2年連続本選でスコア残せませんでした。難しい。
なかなか厳しい問題でしたが、ベンチマークの実行やサーバ環境は快適で、集中して取り組むことはできました。出題の皆様、運営の皆様ありがとうございます。
やったこと
チーム紹介スライドつくりました。おじさんむけ旅雑誌ぽくしてみた

スコアの履歴はこのようになりました、

スコアが伸びない時間がながく、Failも多くありました。
Repositoryはこちらで公開しております
PRつくってマージするスタイルでやっておりましたが、最終的にマージしたPRが38個、マージしてないPRが3個となりました。 うちRevertのPRが7個です。ベンチマークの不整合チェックに引っ掛かり、ブランチで作業し、戻したものもたくさんあります。
最終的にサーバ3台
として利用しました。MySQLの負荷がどうしても下がらず、レプリケーションを行ったのですが、利用できる箇所は本当に少なく、不安定になってしまい、戦略ミスでした。
そのほか、zipを作成ところにhard link(os.Link)を利用し、圧縮率を -1にしたり、singleflightおよびsync.WaitGroupを使ったSQLの並列実行の制御、不必要だったトランザクションの削除などを行いましたが、やっぱり厳しい感じでした。
機会があれば、出せなかったGetGradesのクエリ改善を試したり、業務ではもう何年も使ってない外部キーが性能にどう影響したのか調査をしてみたい。
最後に
今回、事前にインタビュー記事などに載せていただりしました。ありがとうございます。
学生が強くなり、我々は勝つのが難しいのではないか(これも素晴らしいことです)ということも言われておりましたが、今回はfujiwara組の優勝(おめでとうございます!!)と我々平均年齢45歳オーバーのチームでも本選出場とここまではできたので、定年を乗り過ごしてもう少し頑張っていけるのではいかと思います。
今は燃え尽きておりますが、ISUCONが来年も様々な背景をもつ多くのエンジニアと競いあえる場所として開かれ、また挑戦できるといいなと思ってます。
ISUCON11予選に「チーム中目黒乗り過ごし」で参加し本選出場決まりました
ISUCON11の予選に参加し、なんとか本選出場を決めました!チームは去年と同じ「中目黒乗り過ごし」でメンバーも変わらず、hanabokuro氏、mtokioka氏と参加しました。
チーム中目黒乗り過ごしとして、2年連続で9位で本選出場です。去年の予選記事はこちら。
ちなみに、去年の本選はFailでした。
先日ISUCONのインタビュー記事に載りましたので、こちらもどうぞ
今回の問題

ISUのコンディションを収集し、可視化するサイトということで、IoTや大量のネットワーク機器の監視メトリクスの扱いが課題のネタとなっていたように思いました。
世界観が面白く、ISUが投擲の道具じゃなく、愛される存在になったのだと感慨深いものがありました。
構成とスコア
当初は1台でやっておりましたが、最終的に3台を次のように使いました。

getTrendの生成負荷が高かったので、nginxとgetTrendだけを処理するappを用意し、その他を別のappに寄せました。
スコアはこんな感じで推移。

ベストスコアは 684,624 ですが最終的には 289,148 でした。
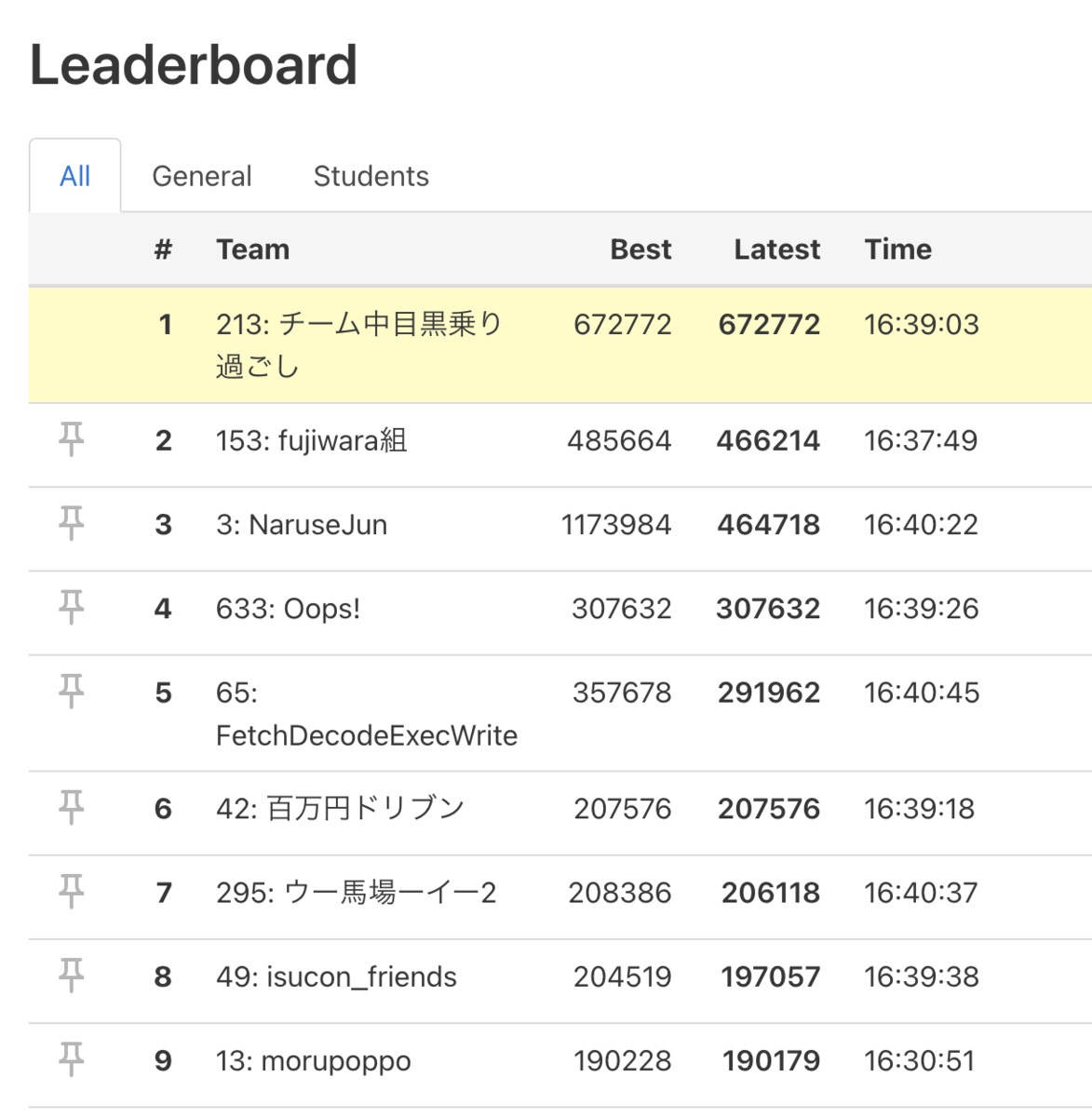
17時の時点では、トップでしたのでパブリックスコアボードでしばらく1位でした。ちょっとうれしい。
使ったツール・言語
DBのクエリの分析に、pt-query-digest を使い、アプリケーションの方にはGCPの Cloud Profiler をいれてどこに時間がかかっていそうかを見ていました。
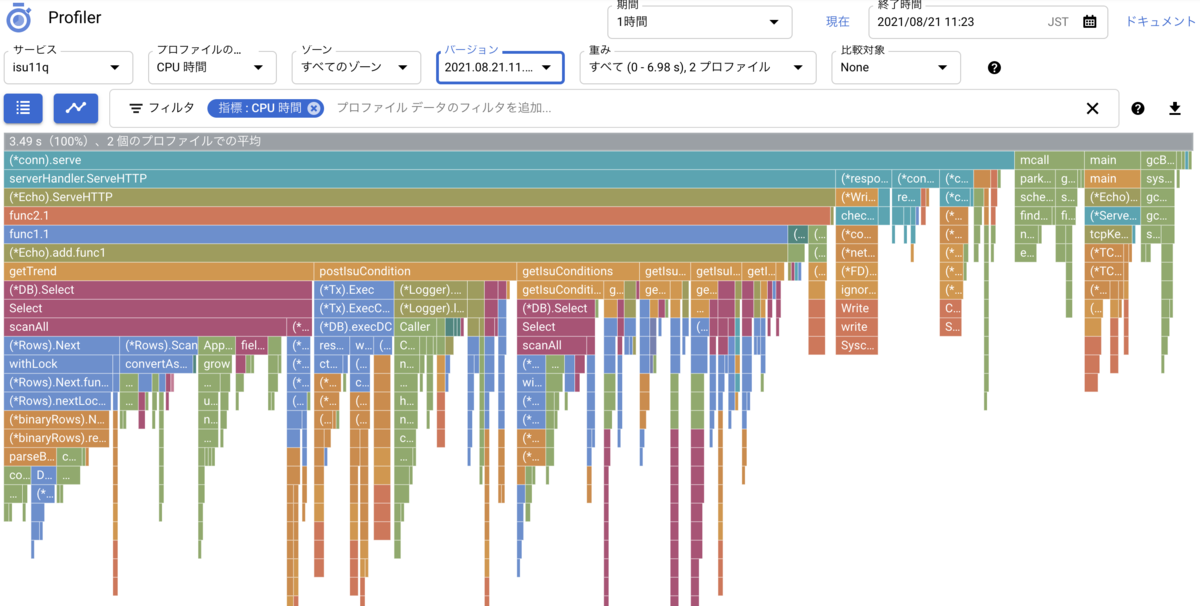
これは 11:20ごろのprofileのスクリーンショットです。
言語は Go になります。わかりにくいところは Perl も参考にさせていただきました!
やったこと
使った repository はここで公開しています
前半
まずtopをみて、DBの負荷が目立ち、INSERTも多くあることがわかったので、MariaDBの設定を行いました。MySQLではなかったのは一瞬悩みましたがそのままにしています。。
sync_binlog = 0 innodb_doublewrite = 0 innodb_flush_log_at_trx_commit = 2 innodb_flush_method = O_DIRECT_NO_FSYNC innodb_adaptive_hash_index = 0
複数台にする際にbind-addressを消した以外はいれたのはこれだけです。
そして、getTrendの生成をbackgroudに回したり、icon画像が不要なところではselectしないようにしたり、必要なindexを張ったりしていたのが序盤です。スコアは2万を超えたあたり。
中盤 (13時すぎ)
Goのapplicationはアクセスログを吐くようになっていて、syslogに負荷がかかり、またログが見づらくなるので、ログのミドルウェアを外しつつdebugモードも解除。
さらに1台ではスコア向上が難しいと考え、複数台構成に変更し、このタイミングでデプロイを簡単にするMakefileを作りました。
この時間帯には、getIsuConditionsFromDB の負荷を下げるため、isu_condition テーブルに condition_level カラムを追加した。
スコアは 10万近くまで上昇。
終盤 (15時すぎ)
捨てるデータの割合であるdropProbabilityを0.5まで下げてスコアが上がるのを確認。
generateIsuGraphResponse でDBからデータを取ってくるところにBETWEENを入れ、不要なデータを取得しないよう対応し、getIsuListのN+1を解消、getTrendにLIMIT 1を追加するなどして、16:50ぐらいには、dropProbabilityをもっと下げて、ベストスコアの68万点がでた。
途中中断
17時ちょっと過ぎたところで、スコアがぐっと下がってしまい 26万点となってしまう。この理由が分かっていない状態で、中断となったのが我々には痛かった。中断の間は、kernelパラメータいれたり、再起動の試験をして過ごす。
再開後、applicationのmax file descriptorに引っかかっているがわかったので、それをいれてみるなどしたが、スコアは戻らず、最終スコアは32万点でおわり、あとはFailしていないことだけを祈る形となった。
まとめ
Failせず、本選出場できるスコアが出せたのは嬉しい。中断前のスコアがなぜ出せなかったのかは、今後の課題としたい。
今回の問題、ぱっと見シンプルなようで、ボトルネックが変わっていくところなど、奥が深いように感じました。加点ルールをより生かせれば、もっと高いスコアが出せるような気がするので、時間があるときに挑戦したいと思います。
また、環境構築、ベンチマーカやポータルも丁寧に作られており、競技に集中できるようなっておりました。おそらく準備は大変だったと思います。運営のみなさまありがとうございました。本選も楽しみです。よろしくお願いします。
今回、ちょうど17時にトップに立てたので、家族にはいいところを見せられたようです。いつも応援ありがとー。本選もFailしないよう頑張ります。
さくらインターネットの新PaaSの「Hacobune」で phpMyAdmin と WordPress を動かす
昨日オープンベータが開始されたさくらインターネットの新しいPaaS、DockerイメージやGitHubとの連携することで、インフラにとらわれることなく、アプリケーションのデプロイができるようになっています。データベースや永続ボリュームがすでにサポートされ、今後、WebサービスやSaaSの基盤として、またチームでの開発に適した機能が拡充されていく予定です。
さっそく試していただき、記事を書いていただいています。ありがとうございます。
この記事ではサンプルのアプリケーションとして、MySQLアドオンを使い phpMyAdminとWordPress を立ち上げてみます。
プロジェクトの作成
さくらのクラウドのホームからHacobuneのコンソールへ移動し、新しいプロジェクトを作ります。

ここでは名前は hacopress としました。
Read moresacloud/autoscaler でさくらのクラウドの水平スケールを試す
さくらのクラウドでオートスケールを実現する sacloud/autoscaler が v0.1.0 で水平スケールに対応したので試してみます。
yamamoto_febc さんのさくらのイベントでの発表資料はこちら
sacloud/autoscalerの構成を知るためにはこの資料を最初に目を通すのをお勧めします。
またv0.1.0 以前からサポートしている垂直スケールにつてはこちらの記事もわかりやすいです!
とりあえず、今回の水平スケールは、サーバの増減とエンハンスドLBにサーバを参加させるところまでを試しました。
準備
サーバを2台とエンハンスドLBを作っておきます。
まず、autoscalerを動かすサーバを作成します。
名前: autoscale1 プラン: 1Core-1GB #最小 NIC: 共有セグメント OS: AlmaLinux 8.4
設定はあとでやります。
次に、エンハンスドLBに参加させるサーバを作成。
名前: base1 プラン: 1Core-1GB #最小 NIC: 共有セグメント OS: AlmaLinux 8.4
このサーバの名前を、下でオートスケールするサーバグループの名前から始まるように設定すると、オートスケールの管理下に置かれ、スケールダウンした際にサーバが削除される可能性があります。
サーバが起動したら、テスト用のnginxをいれておきます
sudo yum install -y nginx sudo systemctl enable nginx sudo systemctl start nginx echo "server name: $(hostname)" | sudo tee /usr/share/nginx/html/index.html echo "OK" | sudo tee /usr/share/nginx/html/live sudo firewall-cmd --permanent --add-service http sudo firewall-cmd --reload
エンハンスドLBを作成し、実サーバとして base1 を追加(サーバグループは gr1 とします)。またproxyされるようルールもつくります。


curlでも動作を確認
% curl https://example.com/ server name: base1
salcoud/autoscalerのセットアップ
まずダウンロードして所定の場所に設置
wget https://github.com/sacloud/autoscaler/releases/download/v0.1.0/autoscaler_linux-amd64.zip unzip autoscaler_linux-amd64.zip autoscaler sudo install autoscaler /usr/local/sbin
systemdのunitファイルもダウンロードして、/etc/systemd/system以下にコピーします。
wget https://raw.githubusercontent.com/sacloud/autoscaler/main/examples/systemd/autoscaler_core.service sudo cp autoscaler_core.service /etc/systemd/system/
次に、autoscaler coreの実行ユーザを作成し、必要なディレクトリを作っておきます
sudo useradd -s /sbin/nologin -M autoscaler sudo mkdir -p /etc/autoscaler sudo mkdir -p /var/run/autoscaler sudo chgrp autoscaler /var/run/autoscaler/ sudo chmod 770 /var/run/autoscaler/
また、autoscaler coreサーバの起動時の環境変数を設定するファイルを /etc/autoscaler/core.config に作ります。
$ cat /etc/autoscaler/core.config OPTIONS="--addr unix:/var/run/autoscaler/autoscaler.sock --config /etc/autoscaler/autoscaler.yaml --log-level info" SAKURACLOUD_ACCESS_TOKEN="" SAKURACLOUD_ACCESS_TOKEN_SECRET=""
TOKEN, SECRETはさくらのクラウドのコントロールパネルから作成して設定してください。
さて、最後にオートスケールに関する設定をします。今回は以下のようにしました。
resources:
- type: ELB
name: "hscale-elb"
selector:
names: ["tk-elb"] #エンハンスドLBに設定した名前
resources:
- type: ServerGroup
name: "hscale-group" #サーバのプリフィックスにもなります
zone: "tk1a"
min_size: 2
max_size: 5
shutdown_force: false
plans:
- name: smallest
size: 2
- name: medium
size: 3
- name: largest
size: 5
template:
description: "hscale-group"
interface_driver: "virtio"
plan:
core: 1
memory: 1
dedicated_cpu: false
network_interfaces:
- upstream: "shared" # 共有セグメント
expose:
ports: [80] #エンハンスドLBで使われるport番号
server_group_name: "gr1" #エンハンスドLBで使われるグループ名
disks:
- os_type: "almalinux"
plan: "ssd"
connection: "virtio"
size: 20
edit_parameter:
disabled: false
password: ""
disable_pw_auth: true
enable_dhcp: false
change_partition_uuid: true
ssh_keys:
- "ssh-ed25519 …." # サーバにログインするためのssh鍵
startup_scripts:
- |
#!/bin/bash
sudo yum install -y nginx
sudo systemctl enable nginx
sudo systemctl start nginx
echo "server name: {{ .Name }}" > /usr/share/nginx/html/index.html
echo "OK" > /usr/share/nginx/html/live
firewall-cmd --permanent --add-service http
firewall-cmd --reload
# オートスケーラーの動作設定
autoscaler:
cooldown: 180 # ジョブの連続実行を抑止するためのクールダウン期間を秒数で指定。デフォルト: 600(10分)
このファイルを /etc/autoscaler/autoscaler.yaml におきます
おいたら、autoscaler coreを起動します
sudo systemctl enable autoscaler_core.service sudo systemctl start autoscaler_core.service sudo systemctl status autoscaler_core.service
うまく動かない場合はstatusやログを確認するとよいでしょう
sudo journalctl -f -u autoscaler_*
オートスケールの検証
さっそく、スケールアップしてみましょう。
v0.1.0では対象のサーバが一台もないときに、スケールアップができない問題があるので desired-state-name をつけて、スケールアップをします。
コマンドは次のようになります。
$ sudo autoscaler inputs direct up --dest unix:/var/run/autoscaler/autoscaler.sock --desired-state-name smallest --resource-name hscale-group status: JOB_ACCEPTED, job-id: hscale-group
リソースとして、サーバグループの指定も必要です。 smallestの状態にするため、2台サーバが作成されていきます。
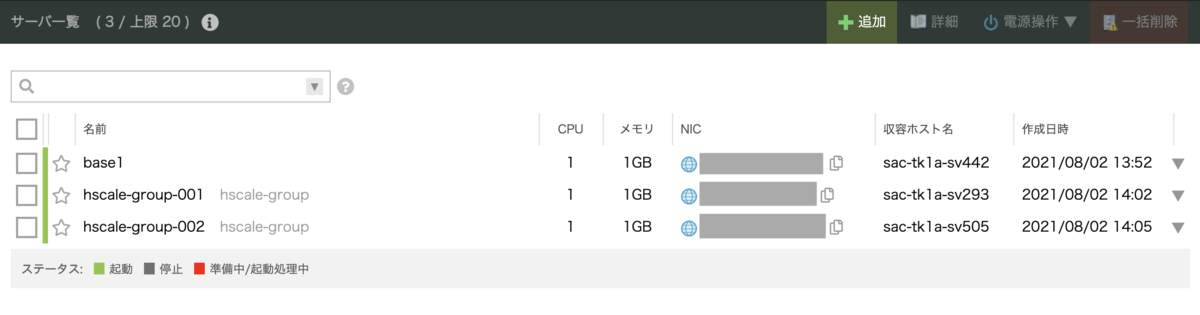
ロードバランサーにも追加されています

autoscalerのログでも作成の様子が確認できます。
Aug 02 14:01:45 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:45+09:00 level=info message="autoscaler core started" address=/var/run/autoscaler/autoscaler.sock
Aug 02 14:01:59 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:59+09:00 level=info request=Up message="request received"
Aug 02 14:01:59 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:59+09:00 level=info request=Up source=default resource=hscale-group status=JOB_ACCEPTED
Aug 02 14:01:59 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:59+09:00 level=info request=Up source=default resource=hscale-group status=JOB_RUNNING
Aug 02 14:01:59 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:59+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=ACCEPTED
Aug 02 14:01:59 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:59+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING
Aug 02 14:01:59 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:01:59+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log=creating...
Aug 02 14:02:06 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:02:06+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log="created: {ID:113301403488, Name:hscale-group-001}"
Aug 02 14:02:06 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:02:06+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log="creating disk[0]..."
Aug 02 14:04:46 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:04:46+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log="created disk[0]: {ID:113301403491, Name:hscale-group-001-disk001, ServerID:113301403488}"
Aug 02 14:04:46 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:04:46+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=RUNNING log=starting...
Aug 02 14:05:35 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:05:35+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id="(known after handle)" name=hscale-group-001 step=Handle handler=server-horizontal-scaler status=DONE log=started
Aug 02 14:05:35 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:05:35+09:00 level=info request=Up source=default resource=hscale-group type=ServerGroupInstance zone=tk1a id=113301403488 name=hscale-group-001 step=PostHandle handler=elb-servers-handler status=ACCEPTED
… 中略 …
Aug 02 14:09:13 autoscale1 autoscaler[451218]: timestamp=2021-08-02T14:09:13+09:00 level=info request=Up source=default resource=hscale-group status=JOB_DONE
ここからさらにスケールアップするときは、
sudo autoscaler inputs direct up --dest unix:/var/run/autoscaler/autoscaler.sock --resource-name hscale-group
スケールダウンする時は、
sudo autoscaler inputs direct down --dest unix:/var/run/autoscaler/autoscaler.sock --resource-name hscale-group
となります。
autoscaler coreの設定時に指定した通り、一度スケールアップ・ダウンをしてから cooldownの 180秒はコマンドを受け付けません。コマンドの結果は次のようになりました。
$ sudo autoscaler inputs direct up --dest unix:/var/run/autoscaler/autoscaler.sock --resource-name hscale-group status: JOB_DONE, job-id: hscale-group, message: job is in an unacceptable state $ echo $? 0
まとめ
sacloud/autoscalerではprometheusなどからwebhookを受け取ってスケールアップ・ダウンするサーバを起動できたりするので、監視ツールが整備されている場合、そこからのwebhookを受け取ってスケールアップやスケールアウトが実現できそう。それ以外でも今回使ったCLIツールをcronなどで実行することで、時間帯に合わせてサーバを増減させたり、必要なサーバ台数をキープすることもできそうです。
うまく使えると運用が楽できそうー
さくらのクラウド GSLB で IPv6 対応した話
5/13 にさくらのクラウドのGSLBサービスにて、実サーバとしてIPv6のアドレスを登録できるようなリリースを行いました。
この機能拡張により、これまでのIPv4に加え、IPv6でもシステムの可用性を向上させることができるようになりました。
GSLBを簡単にいってしまうと「高可用・分散環境に置かれたヘルスチェック付きのDNSサーバ」です。
今回、ヘルスチェックの部分においてIPv6の実サーバへのリーチャビリティを確保し、実サーバとしてIPv6のサーバを登録した際に、AAAAレコードを返すことができるようになりました。今のところIPv6でのDNSの問い合わせは対応しておらず、IPv4での問い合わせのみになります。
GSLBにて重み付け応答「無効」を設定し、実サーバとして、IPv4のアドレス「203.0.113.4」「203.0.113.5」、IPv6アドレス「2001:db8::4」「2001:db8::5」を登録した際のDNSレスポンスは次のようになります
% dig +nocmd +nocomment +nostat site-NNNNNNNNNNN.gslb.sakura.ne.jp ;site-NNNNNNNNNNN.gslb.sakura.ne.jp. IN A site-NNNNNNNNNNN.gslb.sakura.ne.jp. 0 IN A 203.0.113.4 site-NNNNNNNNNNN.gslb.sakura.ne.jp. 0 IN A 203.0.113.5 % dig +nocmd +nocomment +nostat site-NNNNNNNNNNN.gslb.sakura.ne.jp AAAA ;site-NNNNNNNNNNN.gslb.sakura.ne.jp. IN AAAA site-NNNNNNNNNNN.gslb.sakura.ne.jp. 4 IN AAAA 2001:db8:1::4 site-NNNNNNNNNNN.gslb.sakura.ne.jp. 4 IN AAAA 2001:db8:1::5
このGSLBサービスは gdnsd というソフトウェアを利用して実現、提供させていただいております。こちらでも紹介しております。
gdnsd はWikipediaのWikimedia Foundationが提供しているOSSです。
各種のヘルスチェック方式をサポートし、Geolocationや重み付けに基づいた応答などに対応している便利なDNSサーバソフトウェアです。
今回、GSLB(gdnsd)のサーバからIPv6のリーチャビリティを用意するにあたり、高可用・分散環境で動作している既存のサーバをリスクを取りながら構成を変更して直接IPv6アドレスを持たせるのではなく、別途IPv4/IPv6デュアルスタック構成のサーバを用意し、ヘルスチェックをそちらのサーバ経由で行うようにしています。

また、既存の動作への影響を減らすため、GSLBに登録されたサービスにIPv6のアドレスが含まれる際にのみ、監視代理サーバを経由するようになっております。
そして、この監視代理サーバで利用しているのが、Go言語で書いたisiusというWebサーバです。
今まで覚えきれない感じのProxyサーバを書いていますが、isiusもその一種になります。これまでサーバやコマンドを実装する際に、IPアドレスとポートを雑に「:」で結合してしまうなどIPv6に配慮しておりませんでしたが、isius実装時は反省や学びが多くありました。
isiusを起動し、
% curl -v localhost:3000/check_ping/3/10/1000/2001:db8:1::4
とアクセスすると、2001:db8:1::4 に対して、1sのタイムアウト、10msecの間隔で3回pingによる監視を行い、その結果を返します。pingだけではなく、GSLBに必要なtcp、http、httpsの監視が実装されています。
https監視の際のURLは
% curl -v localhost:3000/check_https/{method:(?:GET|HEAD|get|head)}/{ip}/{port:[0-9]+}/{expected_status:[0-9][0-9][0-9]}/{host}/{path:.*}
のようになっております。
そして、gdnsdからは外部コマンドを実行するヘルスチェック機能を使い、nagiosのhttp監視コマンド互換の「check_http2」コマンドを使って、正しいレスポンスが返ってくることを監視しています。
service_types => {
http_mon => {
plugin => "extmon",
cmd => ["/usr/local/bin/check_http2","-I","localhost","-p","3000","-u","/check_http/head/%%ITEM%%/80/200/-/live","-e","HTTP/1.1 200","-A","gdnsd-monitor"],
interval => 10,
timeout => 5,
up_thresh => 5,
ok_thresh => 3,
down_thresh => 2
}
}
設定中の「%%ITEM%%」が実サーバのIPアドレスに変換され、コマンドが実行されます。ヘルスチェックでアクセスする際のパスやホストヘッダ、期待するHTTPステータスはお客様がコンソールやAPIで指定できるようになっております。
check_http2ではなくcurlでも監視はできそうですが、自分でつくった監視コマンドは痒い所に手が届くのでこちらを利用しております。check_http2コマンドもgithubにあります。
check_http2の機能は段階的に増えており、さまざまなサービスで利用しています。 一社に一つは、http監視コマンドを作ると便利ですね。
このようにして、GSLBhのIPv6対応を行いました。GSLBはリージョンやデータセンターを跨ぐようなバランシングに使うというイメージがありますが、実際にはシンプルにヘルスチェック付きのDNS-RRとして利用することができます。ボトルネックの少ないロードバランサの代わりとしても利用できます。機会があればご利用くださいませ。
今後もさまざまなサービスの機能追加、改善を行っていきますので、よろしくお願いします。
HAProxy+libslzによるHTTPレスポンスのGZIP圧縮の検証
少し前になりますが、4/8 にさくらのクラウドの高機能ロードバランサーサービスである エンハンスドロードバランサ にレスポンスボディのGZIP圧縮機能を追加しました。
エンハンスドロードバランサのコントールパネルやAPIで、GZIP圧縮を有効にすることで、手軽にWebサイトの表示にかかる時間を短くすることができますので、お試しいただければと思います。
この記事にあるとおり、エンハンスドロードバランサはソフトウェアとしてHAProxyを使っています。
今回、レスポンスのGZIP圧縮対応にあたり、HAProxyにlibslzという圧縮ライブラリを組み込んでおります。GZIP圧縮といえばzlibがもっとも使われると思いますが、事前に比較検証を行った上でlibslzを選択しているので、その紹介です。
ライブラリとベンチマークの環境
libslzはほぼ聞いたことがない圧縮ライブラリでしhaproxyの作者と同じ方がつくっている、省メモリ、CPUコストの低いGZIP互換の圧縮用ライブラリになります。(解凍の機能はありません)
このlibslzとzlibに加え、ちょうど安定版(2.0.0)がでたzlib-ngとlibslzでベンチマークを行い比較を行いました。
zlib-ngはzlibと互換のAPIを提供しながら、新しめのCPUの命令を使うなどして高速化を行ったライブラリです。また Cloudflare-zlibやintelの最適化も取り込んでいます。
ベンチマーク環境は、さくらのクラウドにて、CPU 12コア/メモリ 128GBのサーバをたて、ローカルスイッチににて接続しています。(さくらのクラウドではサーバの搭載するメモリ量によって使える帯域が変わりますが、128GBでは5Gbpsの通信が可能になります)
3台のサーバはそれぞれ、
- Go app (http-dump-request)
- haporxy: Aにreverse proxy
- benchmark (wrk): Bに対してベンチマーク実行
としました。
haproxy サーバのセットアップ
まず zlib-ngのインストール
この記事を書いている現在の最新は、2.0.2ですが、テストした時は2.0.0でしたので、2.0.0を使っております。
# wget https://github.com/zlib-ng/zlib-ng/archive/refs/tags/2.0.0.tar.gz # tar zxf 2.0.0.tar.gz # cd zlib-ng-2.0.0 # ./configure --zlib-compat --prefix=/opt/zlib-ng # make # make test # make install # ll /opt/zlib-ng/lib total 312 -rw-r--r-- 1 root root 184986 Mar 17 09:15 libz.a lrwxrwxrwx 1 root root 22 Mar 17 09:15 libz.so -> libz.so.1.2.11.zlib-ng lrwxrwxrwx 1 root root 22 Mar 17 09:15 libz.so.1 -> libz.so.1.2.11.zlib-ng -rwxr-xr-x 1 root root 126736 Mar 17 09:15 libz.so.1.2.11.zlib-ng drwxr-xr-x 2 root root 4096 Mar 17 09:15 pkgconfig
haproxyのインストール。libslzを有効にしたものと、GZIPを有効にしたバイナリをビルドします。 libslzはyumでインストールしました
yum install -y libslz-devel wget http://www.haproxy.org/download/x/src/haproxy-$HAPROXY_VERSION.tar.gz tar xvfz haproxy-$HAPROXY_VERSION.tar.gz cd haproxy-$HAPROXY_VERSION # USE_SLZ=1を指定すると、libslzが有効 make TARGET=linux-glibc USE_THREAD=1 USE_SLZ=1 USE_OPENSSL=1 SSL_INC=/usr/local/include/openssl SSL_LIB=/usr/local/lib64 make install mv /usr/local/sbin/haproxy /usr/local/sbin/haproxy_slz cd .. rm -rf haproxy-$HAPROXY_VERSION tar xvfz haproxy-$HAPROXY_VERSION.tar.gz cd haproxy-$HAPROXY_VERSION # USE_ZLIB=1を指定すると、zlibが有効 make TARGET=linux-glibc USE_THREAD=1 USE_ZLIB=1 USE_OPENSSL=1 SSL_INC=/usr/local/include/openssl SSL_LIB=/usr/local/lib64 make install
zlib-ngを有効にするときは、LD_PRELOADを使います
# /usr/local/sbin/haproxy -vv|grep zlib Built with zlib version : 1.2.7 Running on zlib version : 1.2.7 # LD_PRELOAD=/opt/zlib-ng/lib/libz.so /usr/local/sbin/haproxy -vv|grep zlib Built with zlib version : 1.2.7 Running on zlib version : 1.2.11.zlib-ng
haproxyの設定は、実際の環境に近づけるためエンハンスドロードバランサの開発環境からコピー・変更しています。また、httpsを有効にし、ベンチマークもhttpsにて行っています。
関係ありそうなところだけ抜き出すとこうなります。
frontend test-163.43.241.14:443
mode http
bind 0.0.0.0:443 ssl crt /path/to/test.pem alpn h2,http/1.1 tls-ticket-keys /path/to/test-tls-ticket-keys.txt
default_backend test-backend-default
compression algo gzip
compression type text/html text/plain text/plain text/css text/javascript application/x-javascript application/javascript application/json text/js text/xml application/xml application/xml+rss image/svg+xml
use_backend test-backend-group1 if { path_reg ^/.*$ }
backend test-backend-group1
mode http
balance leastconn
retries 3
option tcp-check
server 192.168.0.101:3000 192.168.0.101:3000 check inter 10s
haproxyは次のように起動しました。
zlib
# /usr/local/sbin/haproxy -f /path/to/proxy.cfg
zlib-ng
# LD_PRELOAD=/opt/zlib-ng/lib/libz.so /usr/local/sbin/haproxy -f /path/to/proxy.cfg
libslz
# /usr/local/sbin/haproxy_slz -f /path/to/proxy.cfg
ベンチマーク
まず、wrkを使い9KBぐらいのデータが返るURLに対してベンチマークをしました。
無圧縮
$ wrk -d 30 'https://192.168.0.102/nogzip/source?plain'
Running 30s test @ https://192.168.0.102/nogzip/source?plain
2 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 596.21us 231.33us 8.14ms 91.47%
Req/Sec 8.49k 1.50k 10.88k 59.47%
508831 requests in 30.10s, 4.40GB read
Requests/sec: 16904.68
Transfer/sec: 149.66MB
zlib
$ wrk -d 30 -H 'Accept-Encoding: deflate, gzip, br' 'https://192.168.0.102/nogzip/source?plain'
Running 30s test @ https://192.168.0.102/nogzip/source?plain
2 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 832.53us 315.55us 10.56ms 87.28%
Req/Sec 6.11k 690.37 7.61k 64.45%
365934 requests in 30.10s, 1.10GB read
Requests/sec: 12157.29
Transfer/sec: 37.49MB
zlib-ng
$ wrk -d 30 -H 'Accept-Encoding: deflate, gzip, br' 'https://192.168.0.102/nogzip/source?plain'
Running 30s test @ https://192.168.0.102/nogzip/source?plain
2 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 705.03us 371.54us 11.29ms 92.63%
Req/Sec 7.37k 702.16 9.36k 74.04%
440795 requests in 30.10s, 1.62GB read
Requests/sec: 14644.69
Transfer/sec: 55.07MB
libslz
$ wrk -d 30 -H 'Accept-Encoding: deflate, gzip, br' 'https://192.168.0.102/nogzip/source?plain'
Running 30s test @ https://192.168.0.102/nogzip/source?plain
2 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 550.74us 213.55us 10.69ms 93.44%
Req/Sec 9.24k 1.04k 11.72k 61.56%
552642 requests in 30.10s, 2.11GB read
Requests/sec: 18360.29
Transfer/sec: 71.94MB
無圧縮で 16904.68req/secでていたのものが、zlibで圧縮を行うようにすると、12157.29req/secまで下がります。zlib-ngになると、14644.69req/secまであがります。そしてlibslzでは 18360.29req/secとさらにあがり、無圧縮よりスループットがでるようになっています。
この際のhaproxyサーバのcpu使用率(user:vmstatで計測)ですが、無圧縮では15%前後、zlibでは44%前後に上昇、zlib-ngは35%まで下がります。libslzは37%とzlib-ngより若干高くなるようですが、25%スループットがよいのでその影響もあるでしょう。
コンテンツのサイズを、140byteほどのSmall、3KBのMedium、6KBほどのLargeとしてベンチマーク結果をまとめたのが次になります。
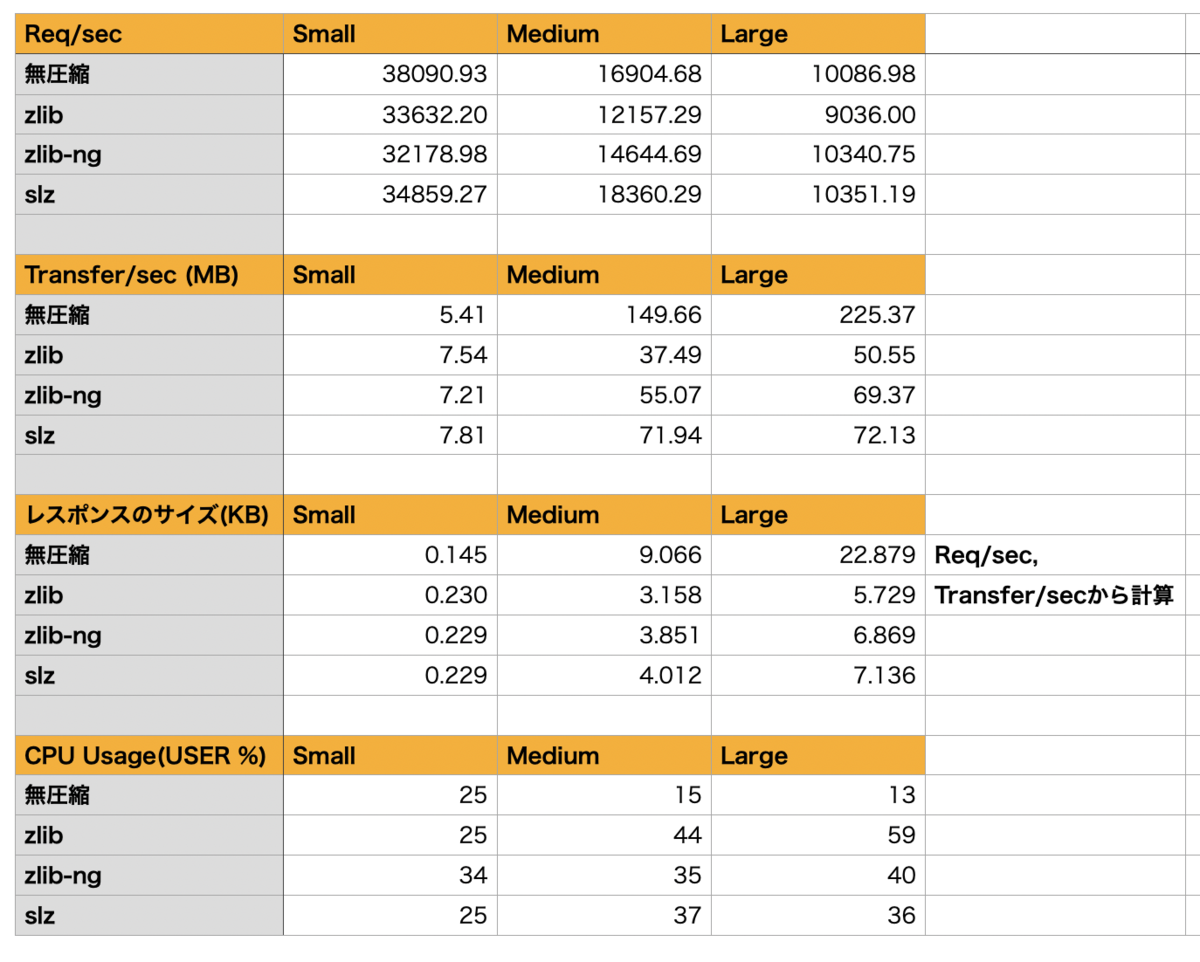
もっともレスポンスのサイズが小さくなるのはzlibになりますが、CPU使用率・スループットへの影響が大きくなります。それに対して、zlib-ngはレスポンスサイズはzlibより大きくなりますが、CPU使用率がさがり、スループットも改善します。ただ、小さいサイズではzlibよりもCPU使用率があがってしまうことがあるようです。libslzでは、zlib-ngよりも若干レスポンスのサイズは増えるものの、CPU使用率はより低くできるようでした。
まとめ
以上のようなベンチマークの結果や、yumでインストールが可能という入手のしやすさ、また、エンハンスドLBにおいては転送量課金ではなくCPS(秒間の新規コネクション数)なので、圧縮率が多少悪くても問題になりにくいことなどを考慮にいれ、libslzを選択し、haproxyに組み込んだ上でエンハンスドロードバランサにてGZIP圧縮オプションの提供を開始しております。
エンハンスドロードバランサをはじめ、今後もさまざまなサービスの機能追加、改善を行っていきますので、よろしくお願いします。